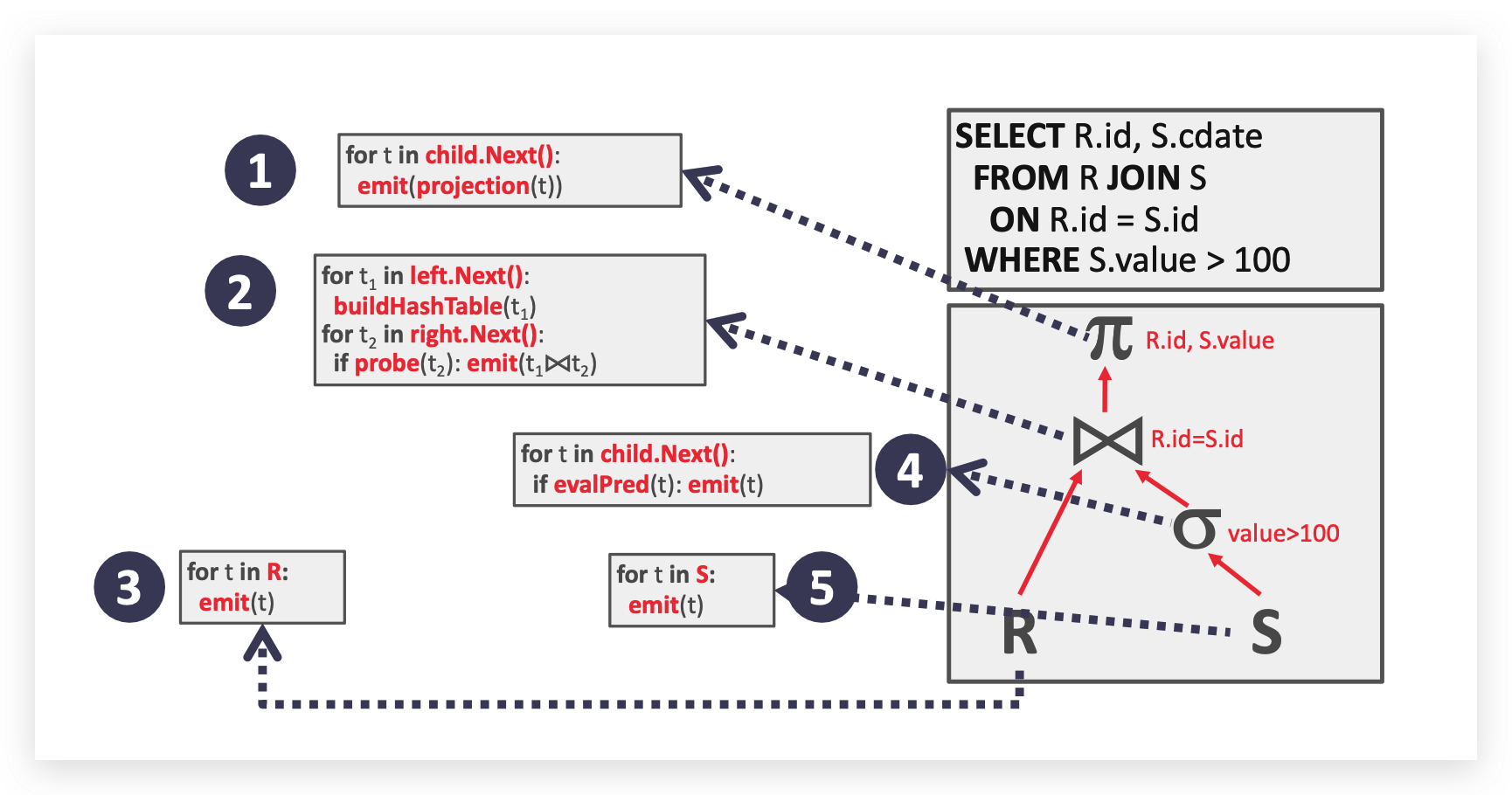
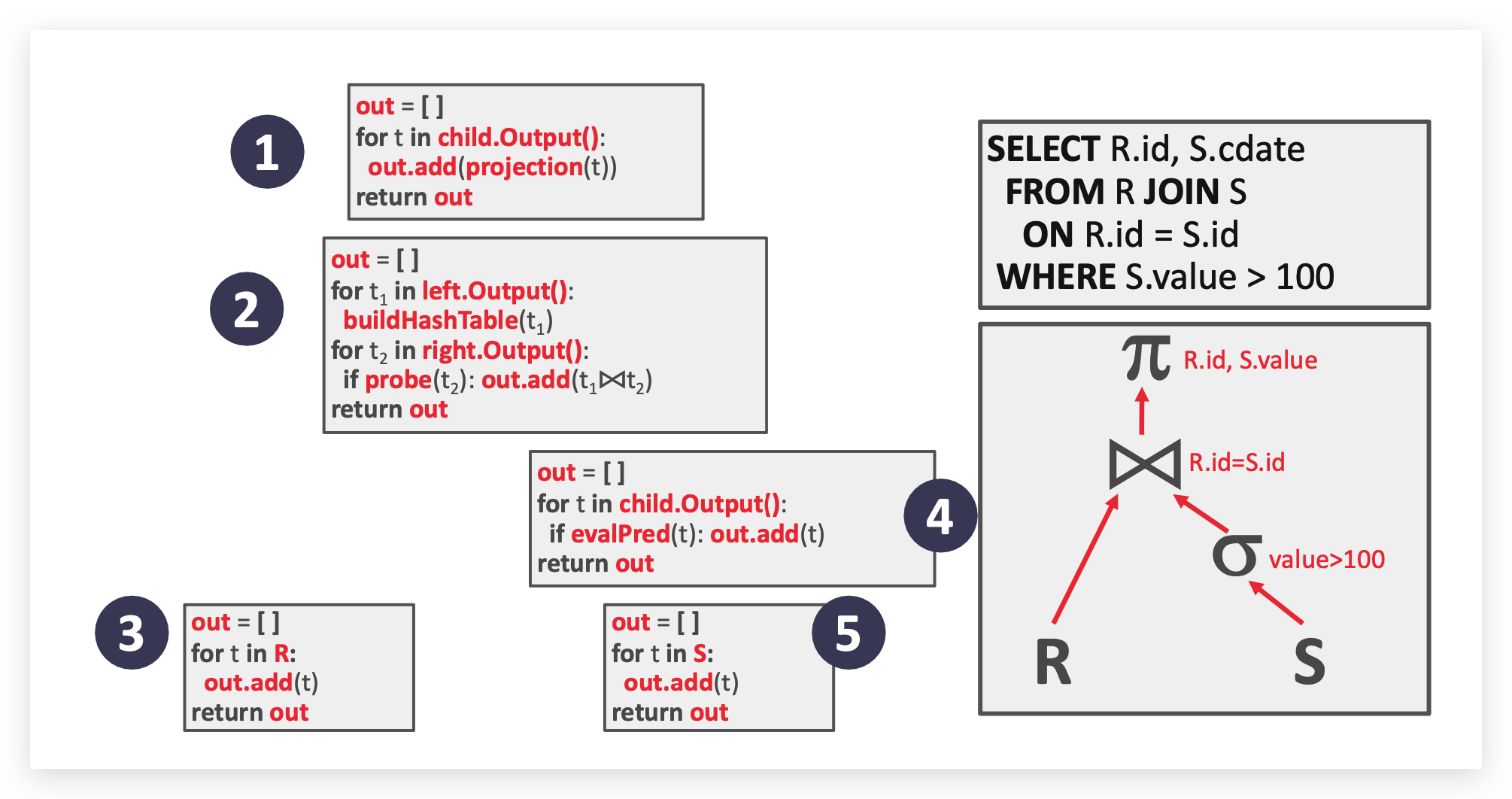
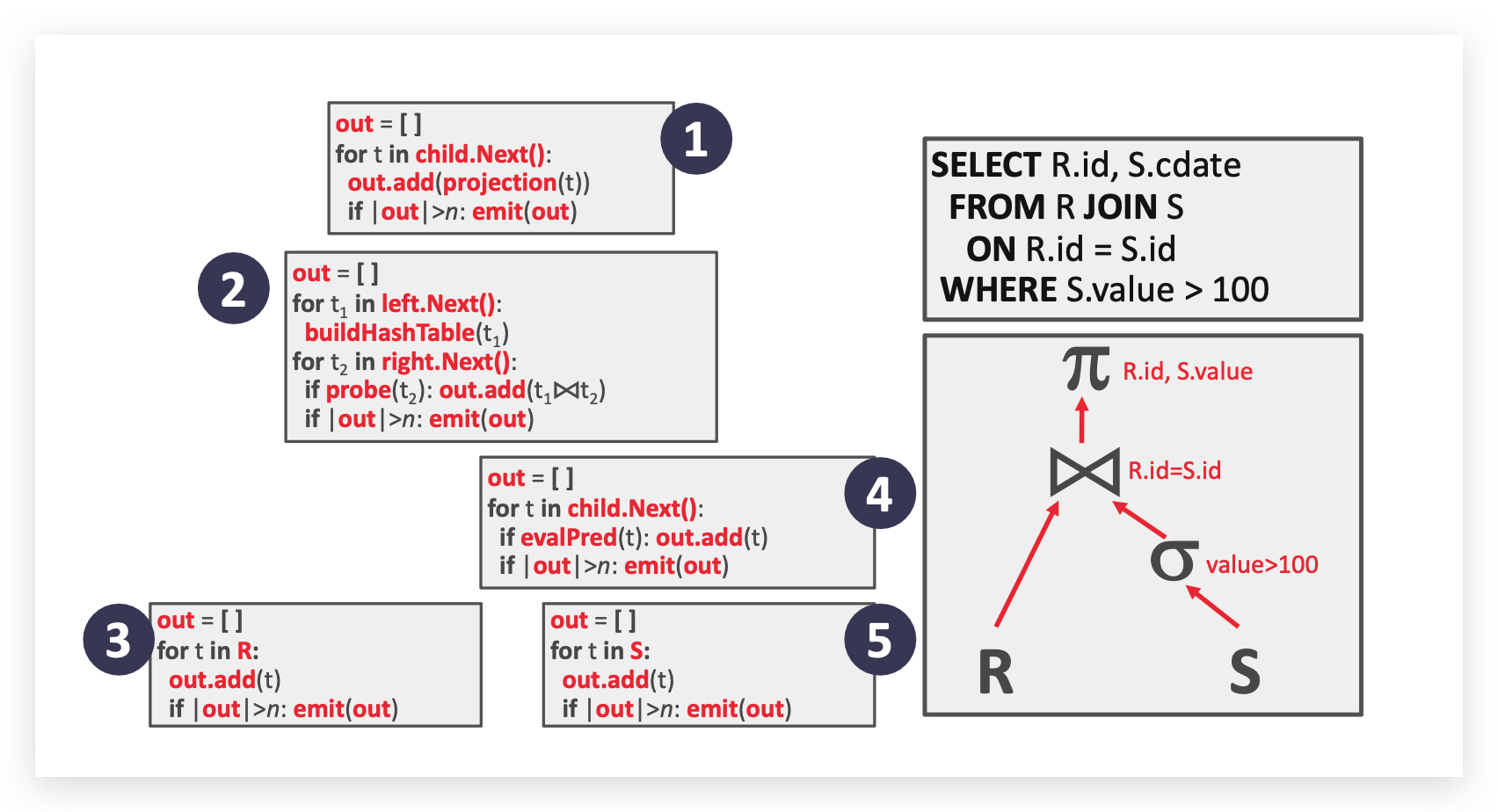
写在前面
我最初的意向是打算出国读个硕士(主要考虑北欧和西欧),大约在8月初左右结束了暑期实习,一直到9月中旬中秋前一直都在准备留学相关工作(成绩、雅思、文书等等),比较闲还上了国外几门很优秀的公开课(具体可见前面几篇文章),最后因为一些家庭因素暂时终止了这个想法。我也了解今年秋招是属于地狱难度,并且这个时间点也已经过了大多数提前批的截止日期,不过好在我自身也属于一个比较善于规划的人,于是在中秋三天里花了一天整理自己的简历,花了一天收集秋招公司信息,再花了一天海投,最后就是数不清的测评、笔试、面试,一直到十月末才差不多结束 ;-(。回顾我的秋招历程,其实并没有太多时间给我准备,基本上就是边面试边复盘总结的过程,于是有了此文。
不过所谓面试指南,经验、技巧等等,我认为都是建立在面试者已经具备了一定合格的能力的基础上,更何况信息安全本身也是一门重视实操的学科。如果面试者自身基础不扎实,哪怕问到了一些准备过的问题,面试官也很容易通过一些 follow-up 的提问问出面试者的真实水平。
关于面试本身,我觉得这不仅是一场测试,一场选拔,更多的可以把它当作一次充满沟通和交流的谈话,所以我们并不需要畏惧。对于面试官而言,他可能只是希望招到一个能够愉快工作的同事、或者一个值得培养的下属;对于面试者而言,其实这是进入职场前少有的可以和业界大佬们直接交流的机会,所以我非常珍惜每一次面试。整个招聘的过程也是候选人和面试官的双向选择,一次好的面试体验会让我对这家公司好感大增 (^-^) ;反之有的面试官态度傲慢、咄咄逼人也会让我情不自禁的打退堂鼓 ಠ_ಠ(非常少数)。
后续内容为我整个秋招经历的思考、心得与总结,包括面试前的准备、面试中的应对以及未来的一些规划。希望可以帮助到同样找工作的同学。
甲方 or 乙方的选择
在秋招之前我已有了两段乙方实习经验,所以个人对乙方的安全产品研发以及红队攻防也有了一定了解。最初我还是向往乙方,因为觉得乙方的工作更加纯粹,并且在某个垂直领域能有比较深入的学习,像一些实验室性质的工作受业务压力影响较少,会有很多时间研究自己感兴趣的东西。产生去甲方的想法是实习一次吃饭时,和华子哥聊到 SAST、以及漏洞挖掘相关话题,在这之前我上过一段时间南大的 程序分析课程 ,但我发现红队向的漏洞挖掘(直白一些就是面向 Pre-GetShell 的审计)更多的还是依靠人工的能力,我也有想过尝试自动化去辅助,但不同项目、业务的代码质量良莠不齐,基本上还是属于审完一套换一套的流水线。这时华子哥和我说如果受限于目前的工作模式,可以考虑去甲方看看。的确在甲方庞大的业务代码下,想只依靠人工直接审计的方式有些不太现实,也衍生出了 SAST、DAST、IAST 等等自动化测试技术以及 DevSecOps 的理念。这一些知识是在乙方环境下比较难去触碰的。
如果是站在甲方的这一点,我们可以考虑的就有非常多了,上到互联网、金融、区块链、最近火热的新能源汽车;下到国企、银行、医疗等等。在甲方公司进行选择的话,抛开物质上的因素(薪资、工作城市等等,虽然这个很重要,不过一般是放在拿到 offer 之后再需要考虑的),我在意的点只有有一个:公司业务是否对安全有真正的诉求,换句话来说就是安全部门是否有真正的话语权。上有喜茶网络安全部门被裁,下有马斯克血洗 Twitter 网安部门,虽然在进入信息安全专业那一天起,我们系主任就嚷嚷着:『没有网络安全就没有国家安全。』但我们不得不承认:安全的确不会带来直接的利益。如果公司对安全没有强诉求,对信息安全建设的重视和投入不足,那么安全部门在公司可能只是一个背锅的存在,在这样的环境下提心吊胆的工作我认为也是一件很痛苦的事情。
简历是一切的开始
我认为简历上最关键的点有以下三项:学历、项目、实习。
- 学历:安全相比于开发,更不用说算法,其实对学历要求还没有那么严格,只不过今年部分公司的个别部门也有本硕 23 所以及目标院校的这一概念。但是学历这一块是定死的,我们也不能改变什么。
- 项目:项目的话分安全开发项目和攻防实战项目两大类,但不管是什么,我认为最好还是遵从 STAR 法则:情境(situation)、任务(task)、行动(action)、结果(result),即在什么背景下,做了什么东西,为什么这样做,取得了怎样的成果。即使是一个 demo 型的小项目或者校园内的简单渗透测试任务,好好准备也是有东西可以聊的。
- 实习:实习同样遵循 STAR 法则,并且实习是基本上每一次面试都会占比较大比重的部分,但与之而来的问题是其实一部分短期实习,我们做的工作有限,甚至有的只是一些打杂的活,这就需要我们主动学习相关领域的知识,毕竟只有知识是永远属于自己的。如果面试官问起来既没有产出,也不知道细节,那不如不写这一段实习经历(面试官给我的原话 )。
除了以上三点,还有一些成果性的荣誉奖项,比如 CTF 比赛、发表的论文、高质量漏洞等等。但对我而言 CTF 基本上面试环节都没有提起过,甚至有些面试官问我 CTF 的全称是什么;漏洞相关也只是大概问一个挖掘思路,不过也可能是因为其并不是属于那种通用框架型漏洞的缘故。
基础需要扎实
这里的基础我分为三样:算法基础、计算机基础、安全基础。
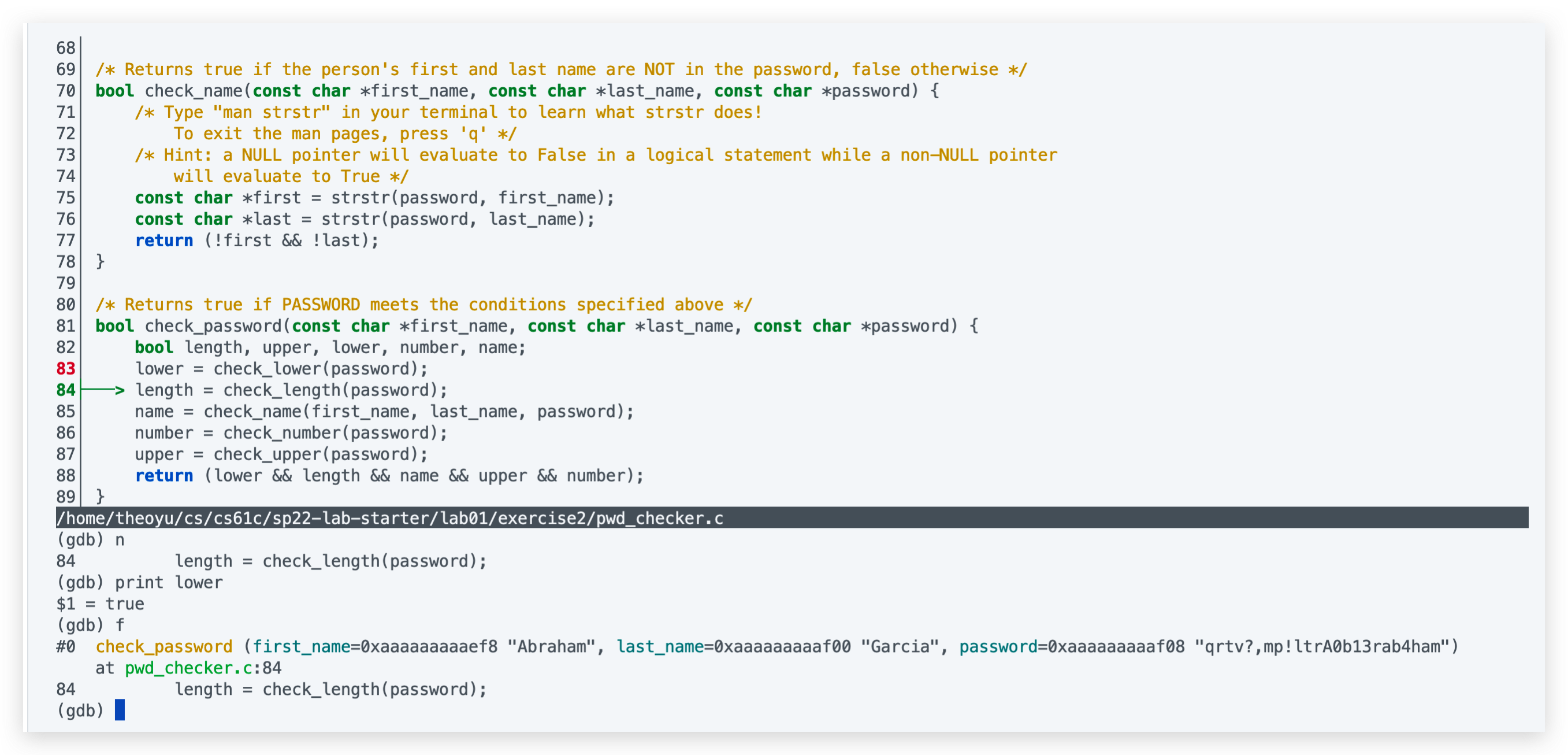
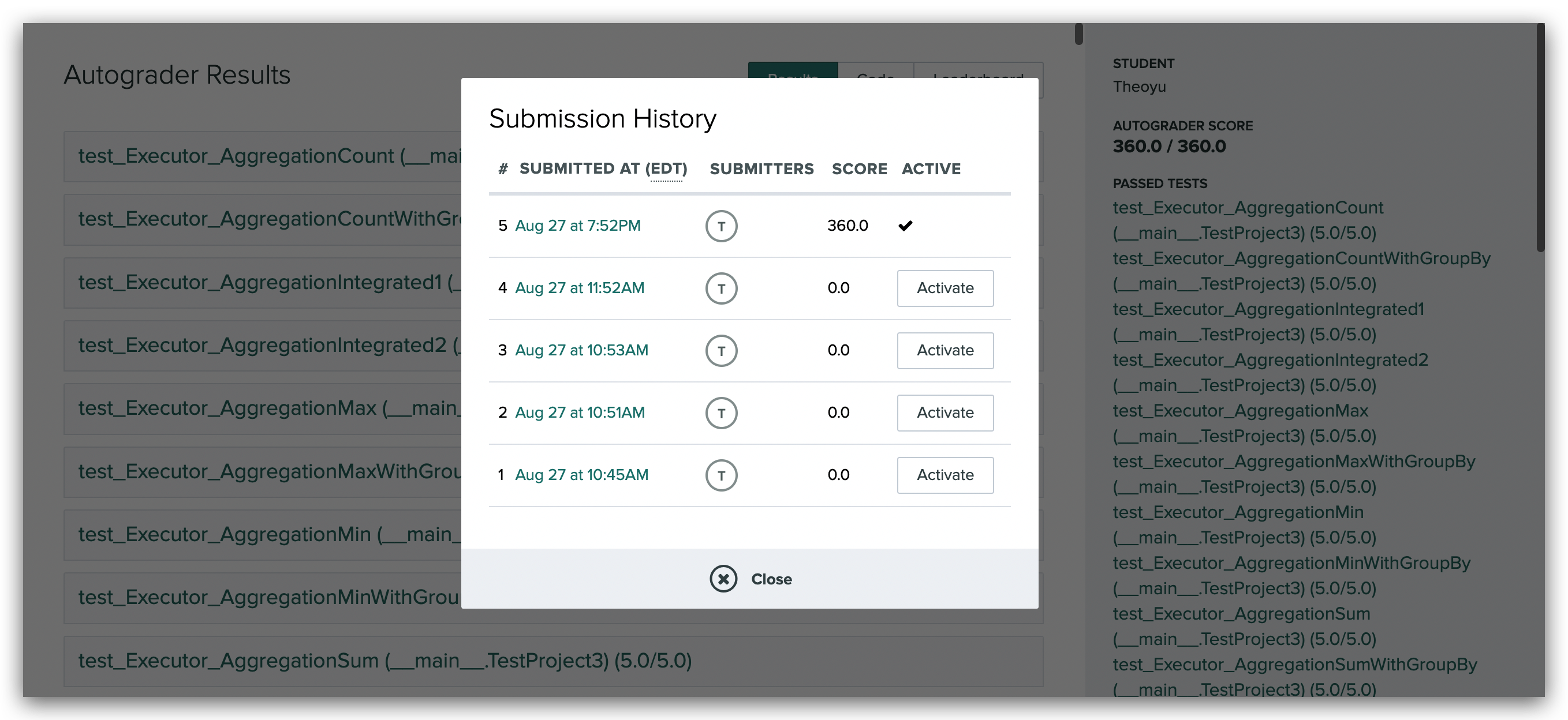
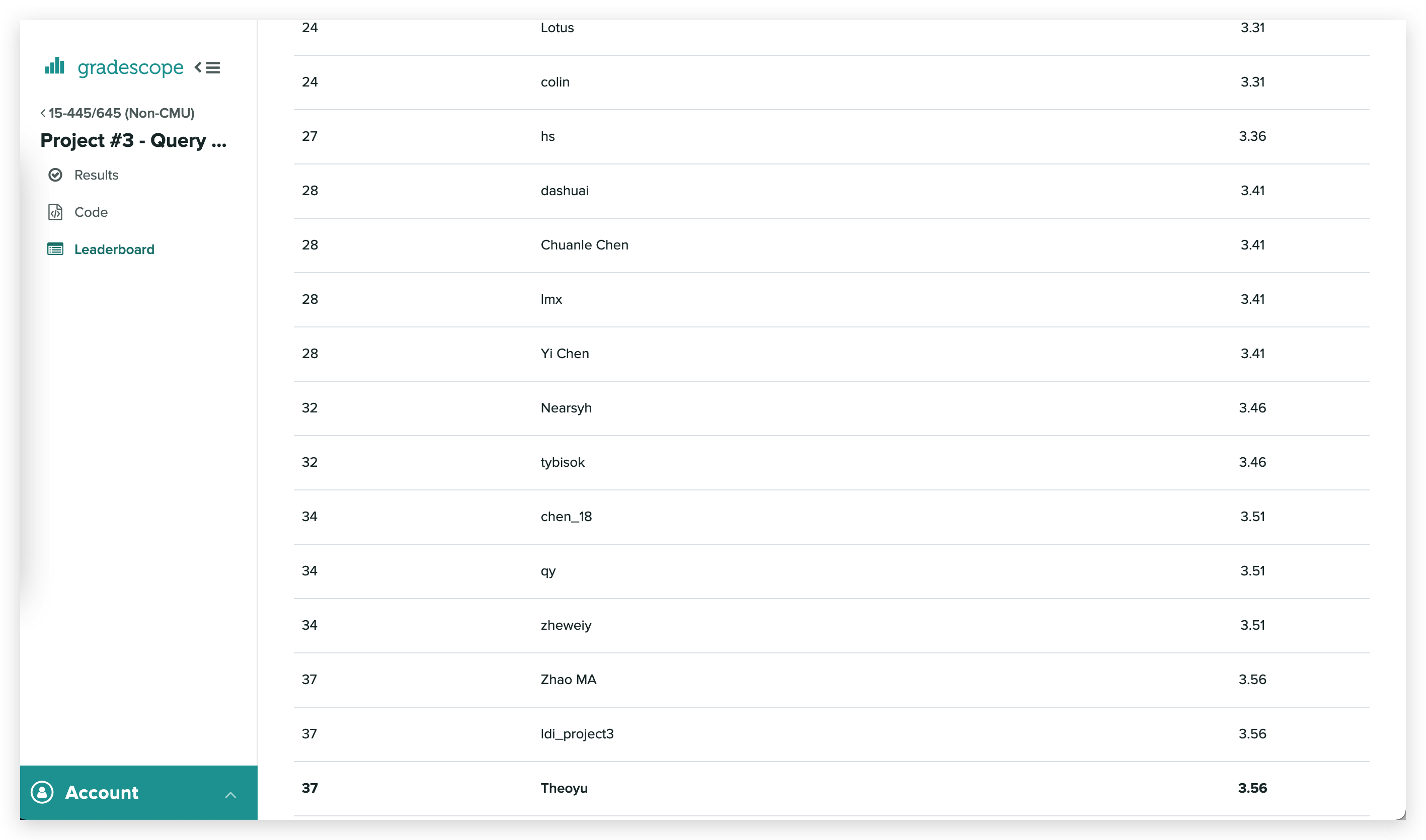
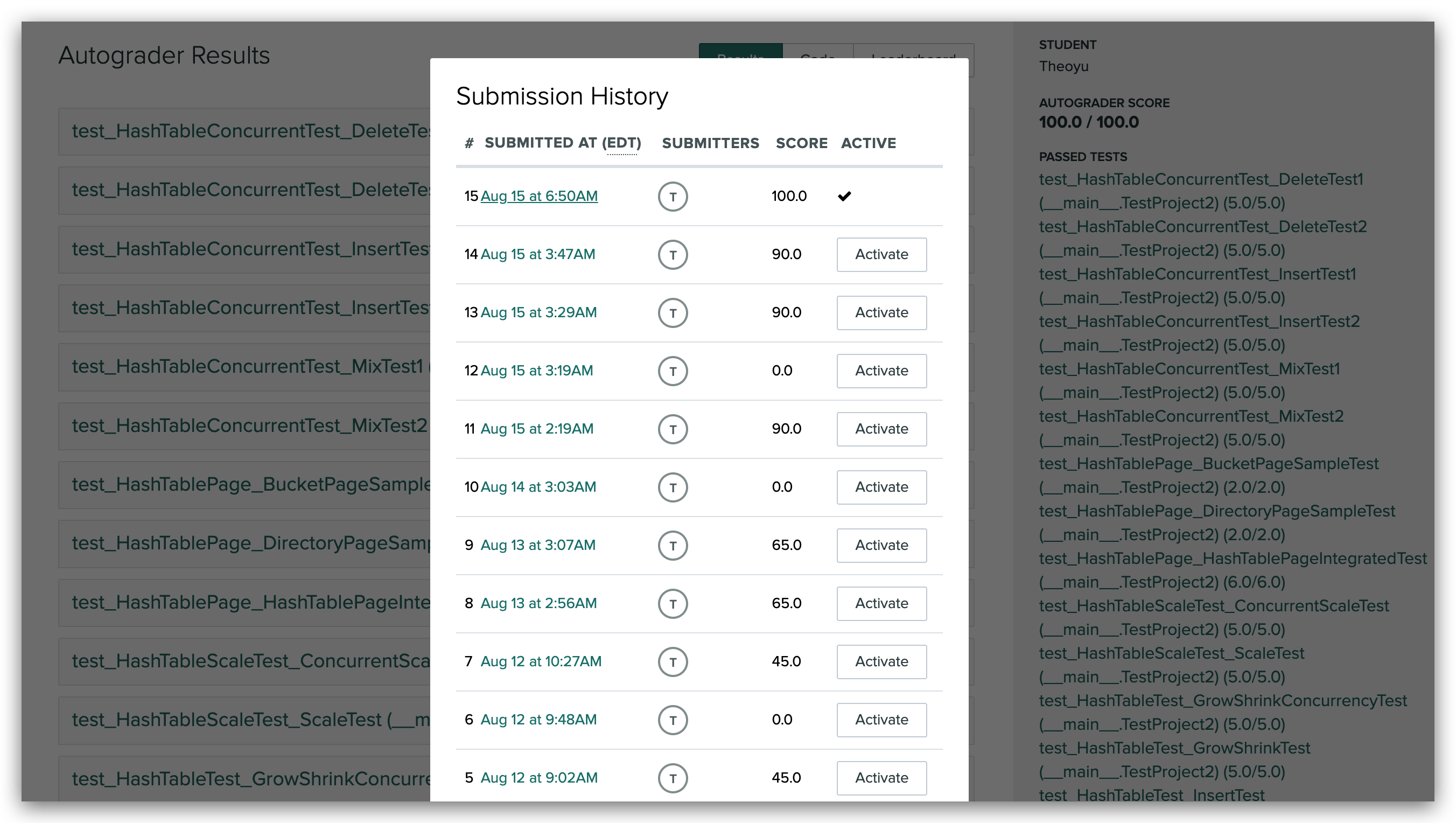
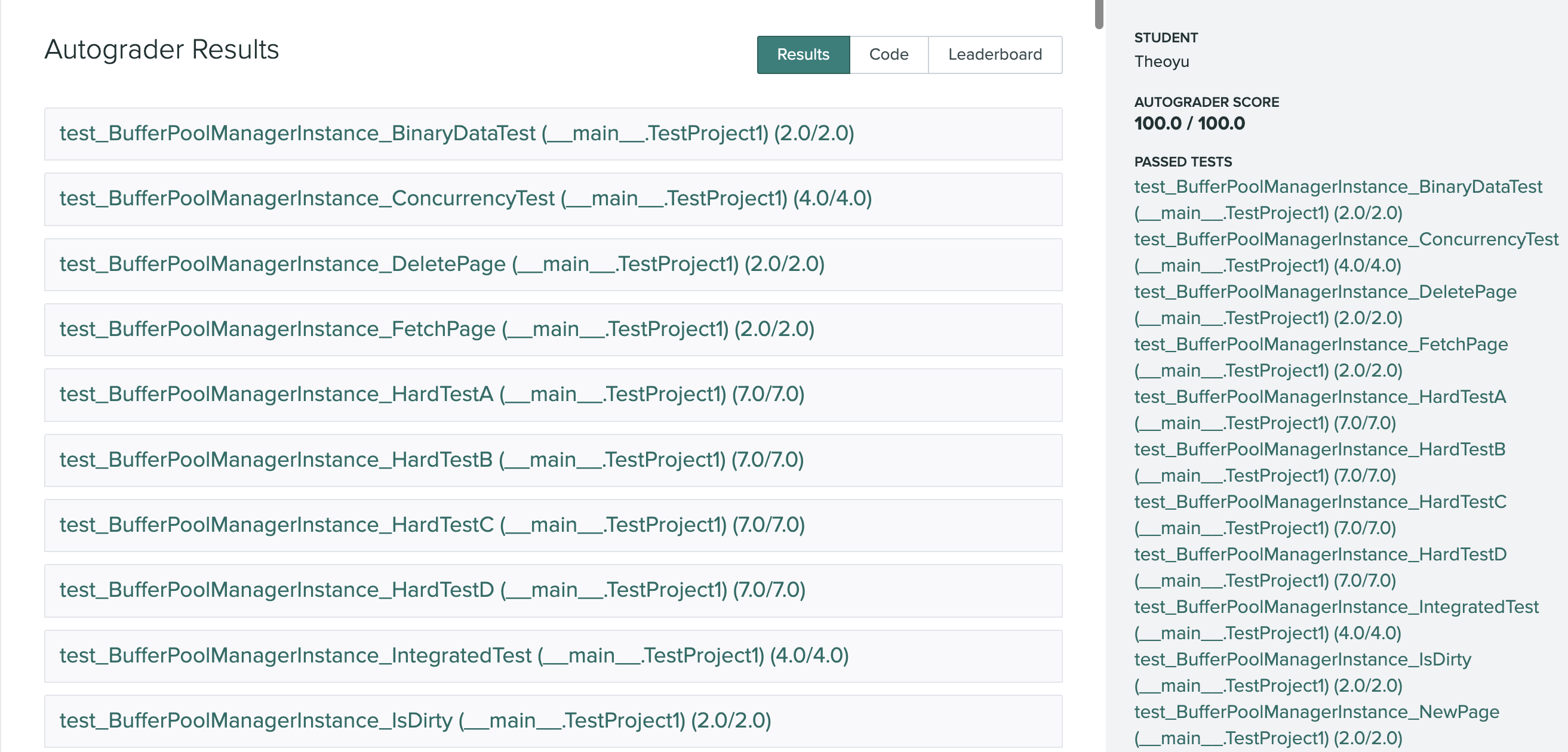
算法基础是很多同学都容易忽视的一点,包括我在春招找实习时,笔试需要做算法的公司我都一律 pass …后来秋招意识到不对,基本上大多数公司的笔试题都有算法,有的甚至和开发放在一起纯算法笔试,不过我还是没有进行系统的准备,大约就简单温习了 STL 一些数据结构的调用。直到中秋后的第一场面试,整体都比较顺利,快结束时面试官说我们走个流程做一道算法吧,卒,然后面试官换了一道,磕磕碰碰写了出来,但结果不对,我说能不能让我在 Clion 上调试一下,面试官看了看时间让我说思路就行,卒 。之后便找了开发的同学,推荐了 代码随想录,大约花了一周,每天 10 小时左右爆刷,因为时间实在是不够,争取做一道就总结一道,前前后后大概做了 100 出头,少部分见下图(贪心和动态规划以及后面刷的一些题目没有纳入其中):
对我而言 100 多题手撕代码基本上足够了,安全方向的话主要以考察基本数据结构为主,当然时间充裕的话最好还是把代码随想录整体过一遍比较好,大约在 200 左右会更加有底气。
计算机基础基本上为计算机网络和操作系统两块,这里一样是开发同学推荐的 小林coding ,当然不建议像八股文那样去背,我觉得简单过一下就行,和之前说的一样信息安全还是一门重视实操的学科。打个比方面试官很少会直接问你 『 TCP 三次握手和四次挥手的过程 』,但是可能会问 『 NMap 支持哪些端口扫描方式,可以分别说说对应 TCP 三次握手和四次挥手的哪一环节吗?』
安全基础因人而异,web 安全的话至少 OWASP Top 10 得非常熟悉,从漏洞原理到利用到预防。这里推荐 Web安全学习笔记 作为自己查漏补缺的资料,当然不同公司侧重点也会很不一样,就拿最基础的 Sql 注入来说,有的公司可能会对利用这一块要求比较高,比如
xxx 被过滤了如何绕过?
如何判断数据库类型?不同数据库打法上有什么不一样?
不同数据库版本之间的各种tricks
但有的公司可能会对原理上考察更加全面:
sql 注入如何预防?
预编译的原理是什么?在业务中有哪些不能使用预编译的点,为什么?
WAF如何检测sql注入、RASP如何检测、了解AST吗?
基础这一块可以选择多看看面经,慢慢总结完善。不过如果是打 CTF 出身并且基础扎实的同学,我认为还是不用太担心的。
找准自己的领域
随着各种业务高速发展,安全行业的需求其实也是逐步增长,人的精力终归有限,找到属于自己的领域对无论自我认知还是发展都非常重要。
在大一刚接触安全时,老师把我们简单分为 Web 和二进制两个方向;后来打 CTF 时,我根据 CTF 的题目类型把安全分为 web、逆向、pwn、密码和杂项(取证、隐写)。这样划分终归还是比较片面,如果我们能对自己有一个深刻的认知,找到一个适合自己的方向,进而在简历和面试中凸显出来,至少能告诉面试官:『 我想做这个方向,我觉得我比较合适 』。
单从网络安全来说,不同的人侧重点可能完全不一样:有的人打点很厉害、手握不少 0day;有的人内网漫游、对各类云环境也非常熟悉;有的人擅长漏扫和白盒、对SDL有自己的理解和实践 …安全同时需要广度和深度,如果能在适合自己的领域长期学习和发展,我觉得是一件很快乐和有价值的事情。
提前应对通用问题
在面试中有很大一部分时间都会交给我们自己来说,就我而言以下问题是基本上每次面试都会问到的:
1. 自我介绍
2. 介绍实习
3. 介绍项目
4. 最有印象的一道CTF题目?
5. 最有意思的一次挖洞/渗透经历?
6. 给你一套代码,如何做代码审计?
7. 给你一个网站,如何做渗透测试?
......
上面这些问题的答案,尽可能提前总结记录下来,能比较流畅的介绍,如果条件允许的话可以说给志同道合的朋友。我和室友就经常会互相模拟面试问答 (*^^*) ,这样比较 open 的方式经常会暴露很多自己看不到的问题,也是收获很多。
写在最后
秋招属实不易,让我最直观的感受就是 个人在大环境下实在渺小,而我很大一部分的焦虑就源自于和别人的比较,后来想开了也就没有那么多的精神内耗。降低预期,减少攀比,顺势而为,毕竟一切都得向前看,不是吗?
受限于我的眼界和水平,文章很多观点可能非常片面和不妥,还请谅解,欢迎批评指正;如果你在阅读之后能有一些收获,那也是我莫大的荣幸。
最后,还要感谢一路上众多师傅以及学长们的指导帮助,
当然,
也要感谢在寒冬下没有放弃的自己。
开启一段新的征途吧。
]]>