我的学习顺序,快速过一遍 Notes,了解一下这一节的大纲和重点,之后根据自己的能力选择是看视频还是直接看 slides(并发控制之前的章节难度还 ok ),学习完一章后,尝试用自己的话把一章的重点梳理一遍,最后选择性阅读帆船书。
以下内容为我归纳整理的一些问答式:
1. 为什么不使用 OS 自带的磁盘管理模块 (mmap)?
2. 存储模型 N-Ary Storage Model (NSM) 和 Decomposition Storage Model (DSM) 的优缺性?
3. 为什么会有 buffer pool?
4. buffer pool 可以做哪些优化?
5. 为什么数据库BUFFER POOL需要LRU-K的策略?
6. 有哪一些哈希方案?
7. 是否当有节点不到 half-full,就 MERGE 节点?
8. B+ 树的优化
9. B+树的 Latch Crabbing 是什么?
10. Lock 和 Latch 的区别是什么?
11. 108个页,内存 buffer pools 中只能容下5个页,怎么利用 General (K-way) Merge Sort 做外部排序?
12. 有哪一些做 aggregation(聚集)的方案?
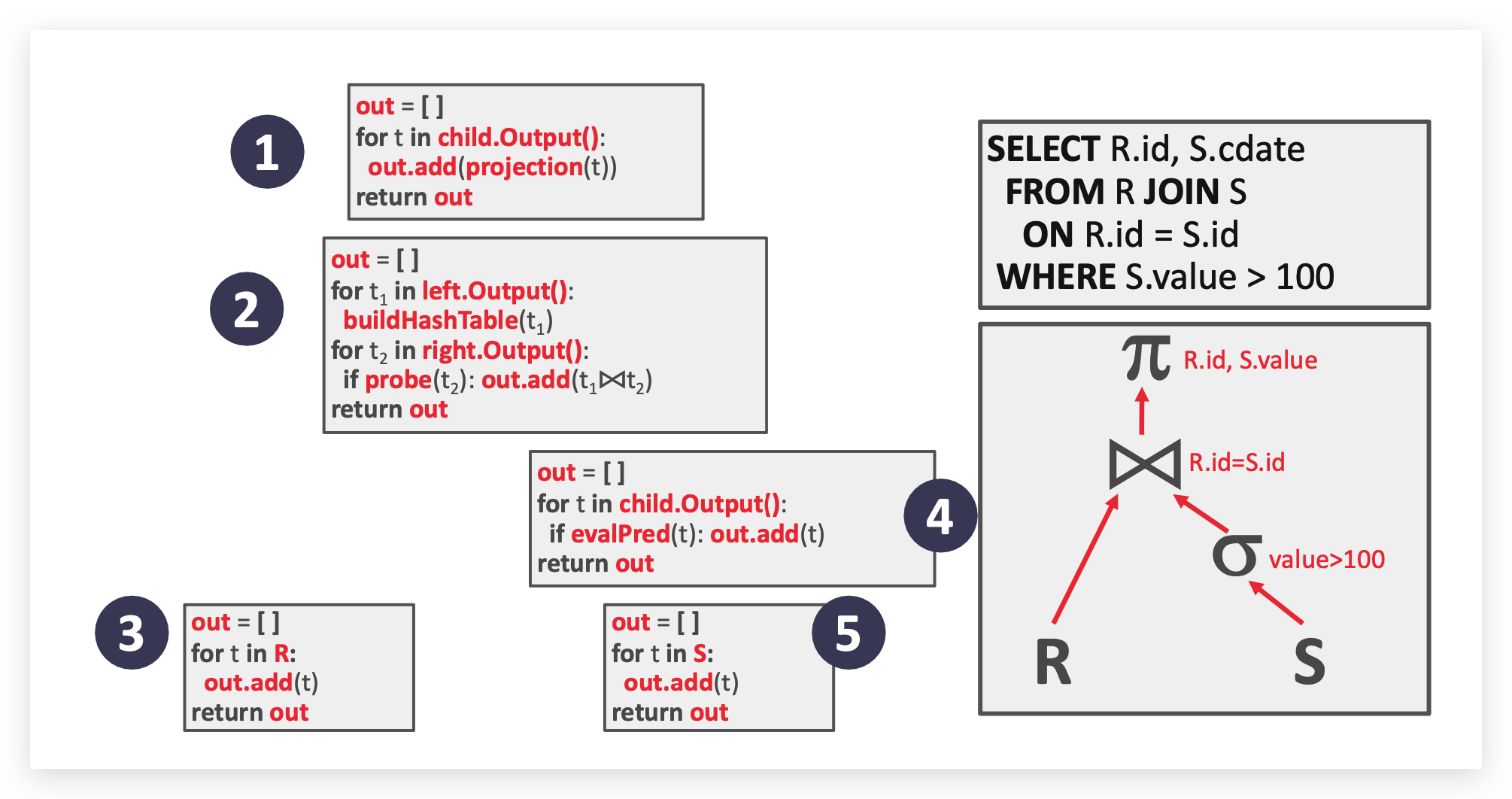
13. join算法有哪些?以下述例子分析复杂的:
14. 有哪一些数据库执行模型?
15. 有哪一些数据读取的方法?
16. 单个 Intra-Query 如何做并行?
17. 谈一谈数据库执行的逻辑优化和物理优化?
18. 简单介绍一下ACID?
19. 如何判断事务的执行顺序(schedule)是否与其串行执行(serial)等价?
20. 什么是 View Serializability?
21. 什么是两阶段锁?如何解决集联中止和死锁的问题?
22. 什么是 LOCK GRANULARITIES ,为什么要这么设计?
23. 如何基于时间戳进行并发控制?
24. 并行事务可能出现怎样的问题?事务有哪几种隔离级别,有什么特点及其实现?
25. MVCC 设计需要考虑哪几个方面?
26. 能否不使用 LOG 实现 undo 和 redo?
27. 什么是 WAL?
-
为什么不使用 OS 自带的磁盘管理模块 (mmap)?
if i die in this class , you want to have a memorial something just Say Andy hated mmap
Andy专门写了一篇论文批判不应该在数据库中使用 mmap :Are You Sure You Want to Use MMAP in Your Database Management System? (CIDR 2022)
简单来说作为底层的操作系统,他只能看到毫无规律的读取和调用,而 DBMS 希望自己拥有足够的控制权。
-
存储模型 N-Ary Storage Model (NSM) 和 Decomposition Storage Model (DSM) 的优缺性?
-
为什么会有 buffer pool?
优点:内存速度大于磁盘
缺点:命中率很低,刷新很快 -> BUFFER POOL BYPASS
把一些查询不放入buffer pool中
-
buffer pool 可以做哪些优化?
- MULTIPLE BUFFER POOLS
- PRE-FETCHING
- SCAN SHARING
- BUFFER POOL BYPASS
-
为什么数据库BUFFER POOL需要LRU-K的策略?
LRU ( Least Recently Used ):最近最久未使用,防止了SEQUENTIAL FLOODING,提高了命中率。
-
有哪一些哈希方案?
-
静态哈希方案:
-
Linear Probe Hashing
线性探测法是开放寻址法(Open Addressing)中的一种,插入元素时,若存在哈希冲突,则往后顺移,直到找到一个空的位置。
线性探测法会导致同类哈希的聚集 (Primary Clustering)。
-
Robin Hood Hashing
罗宾汉是英国民间传说中的英雄人物,劫富济贫,整治暴戾。罗宾汉哈希是线性探测法的拓展,传统的线性探测只是无条件的顺移,而罗宾汉哈希会记录每个键离本来应该插入的位置的距离,当有新的键冲突,往后顺移的同时会比较冲突位置 key 的距离和自身距离的大小,如果自身的距离已经超过冲突的位置 key 的距离,则选择替换该项,顺移被替换的 key 。
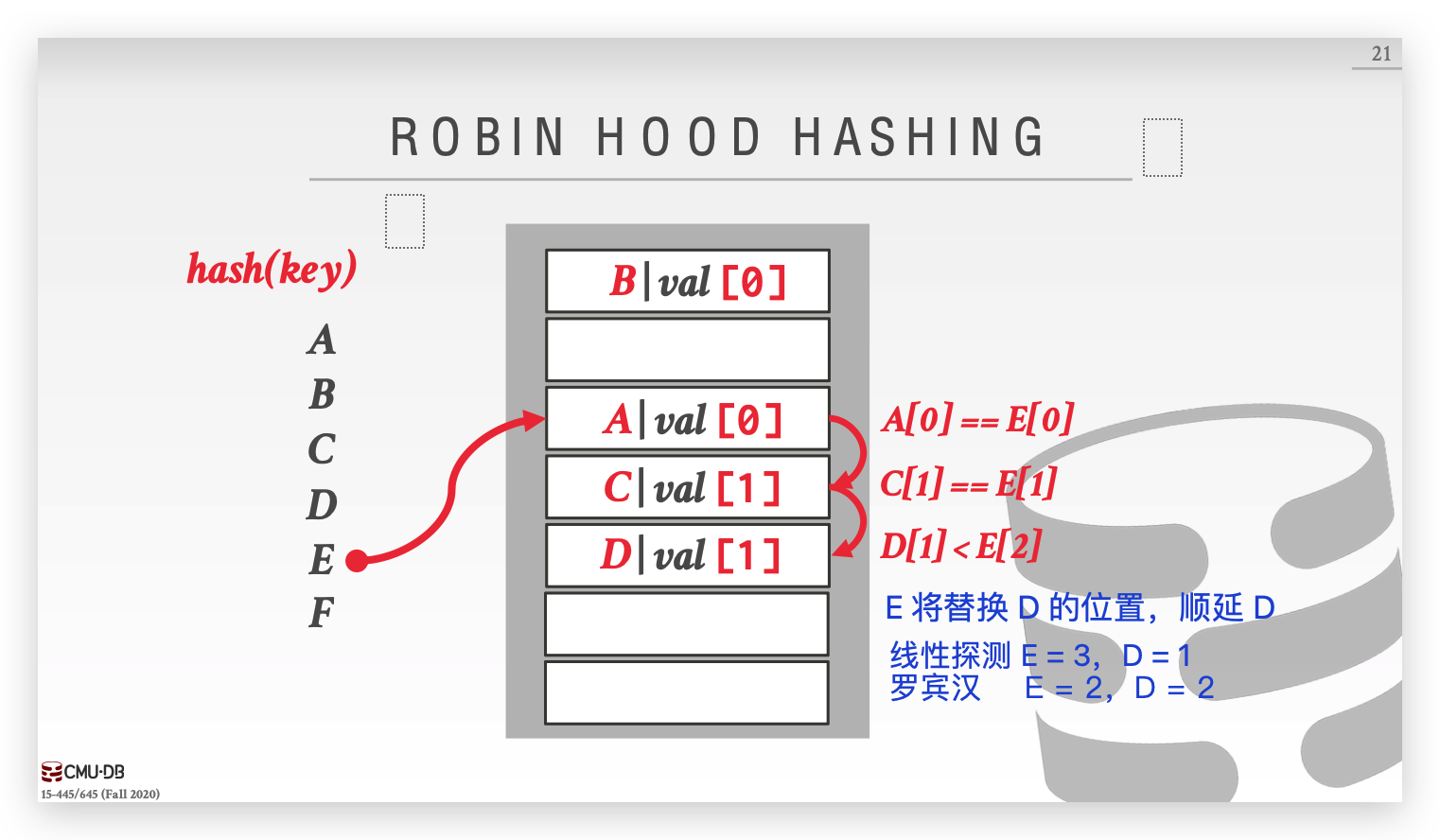
罗宾汉哈希可以显著降低探测长度的方差,把 rich key 的位置交给 poor key,从而使大部分元素的探测长度趋于平均值。但是每次 insert 时又增加了新的比对开销,这是不可避免的。
-
Cuckoo Hashing
Cuckoo Hashing 采用多个 hash table,每个 hash table 都采用不同的 hash function seed 。
对于任何一个 key ,都可以选择其中一个没有冲突 hash table 插入,若全部 hash table 都没有空的位置,则随机选择一个 hash table 中对应的位置插入,并取出原来这位置上的 key 重新插入。
在容量不够的情况下,连锁的冲突可能会导致死循环,解决办法只能扩容然后 rehash。
-
-
动态哈希方案
-
Chained Hashing
每个 slot 维护一个 linked list,对于冲突的哈希则直接追加到链表后面。
如果数据很大链表过长,时间复杂度又退回到 O (n),我们内部会维护一个负载因子(最长链表长度 / slot 个数),当负载因子达到某个阈值便扩容 slot 并 rehash。
-
Extendible Hashing
简单来说 Extendible Hashing = Hash + Trie( 字典树 )
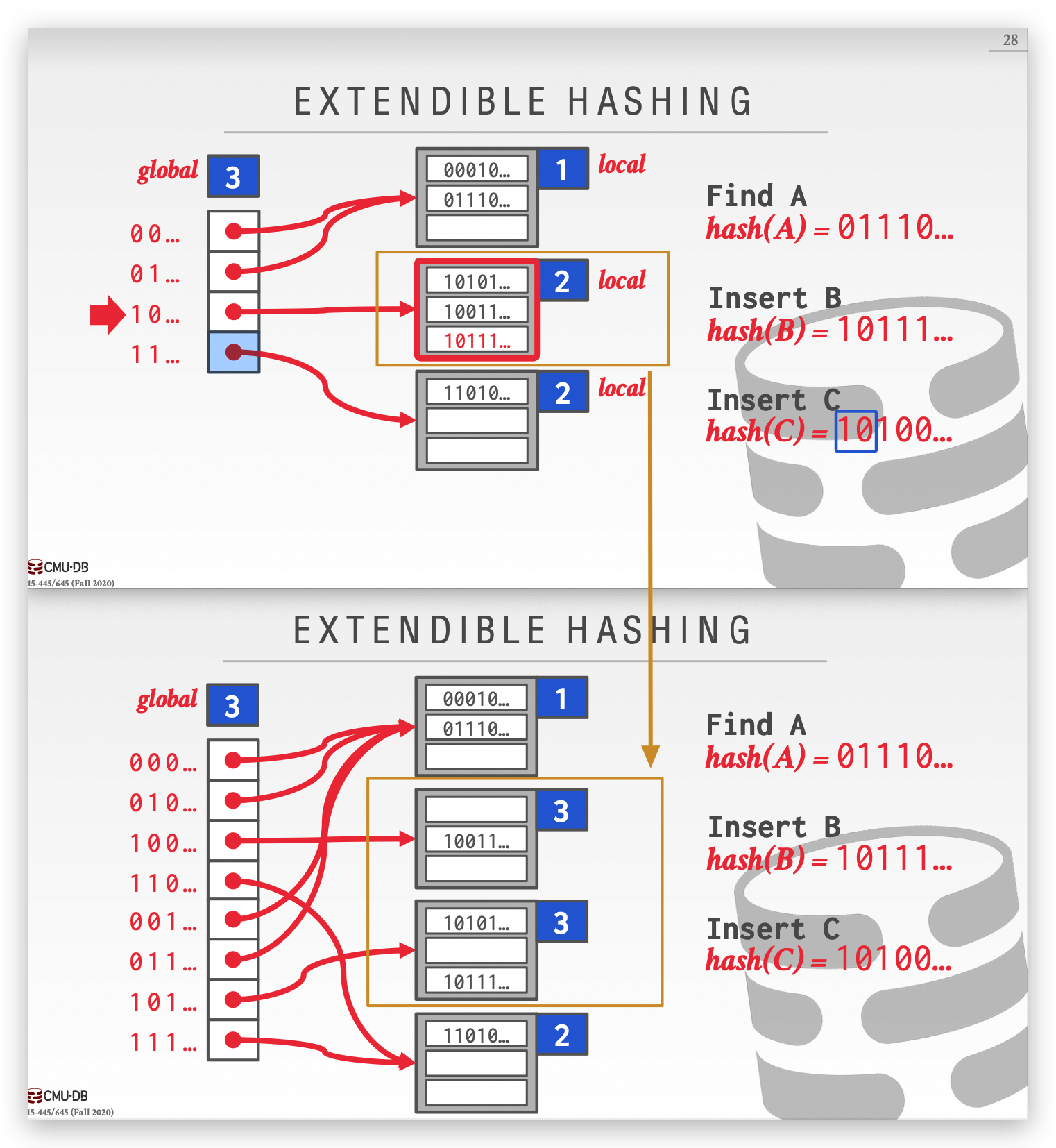
Extendible Hashing 会在 project 2 中实现,详细请见:
-
Linear Hashing
http://queper.in/drupal/blogs/dbsys/linear_hashing
-
-
-
是否当有节点不到 half-full,就 MERGE 节点?
MERGE 有一定的开销,可以先把该节点保存,然后过一段时间周期性的批量处理这些节点(重新建树)。
-
B+ 树的优化
-
Prefix Compression 前缀压缩
在同一个叶子节点上,如果 key 有共同的前缀,可以提取出来节省空间。
-
Suffix Truncation 后缀截断
对于内部节点,如果前面的数据就足够做 ROUTE ,后面的数据没有区分度,那么就可以把没有帮助的部分截断。
-
Bulk Insert
在构建一棵 B+ 树时,如果逐个插入节点可能会比较慢,Bulk Insert 就是先对 key 排序,然后自底向上先生成叶子节点,再根据叶子节点形成内部节点。Bulk Insert 让我们能更快去构建一棵 B+ Tree。
-
Pointer Swizzling
-
-
B+树的 Latch Crabbing 是什么?
因为 B+树会经常涉及到分离和归并,所以我们需要严格进行锁处理。
我们从上到下先拿到父 latch,再拿到孩子的 latch:
- 针对于 read 的情况,只要拿到孩子的读锁,就可以把祖先们的读锁给解开。
- 针对 insert 或 delete 的情况,如果孩子是 safe 的(比如 insert 不会导致分离,delete 不会导致归并),则可以把其祖先们的锁全部解开。
上面这样有一个问题,我们发现根节点始终是一个上锁的状态,这样对效率的影响比较大。我们可以采取一个 『 乐观 』的态度,我们假设叶子节点都是安全的,所以无论是增还是删都先上读锁,等到具体情况如果发现并不安全,则重头再按照写锁的逻辑来一次。
-
Lock 和 Latch 的区别是什么?
Lock 是一个高级别,逻辑意义上的锁,一般特指事务锁,用于保护数据库内容免受其他 transactions 的影响 ,而且需要考虑一个事务回滚的问题。
Latch 是一个低级别的锁,用于维护 DBMS 内部数据结构在多线程情况下安全读写,比如互斥锁 mutex。
-
108个页,内存 buffer pools 中只能容下5个页,怎么利用 General (K-way) Merge Sort 做外部排序?
- 第一轮:108个页每次放入5个页进行排序,排序后写入磁盘,这样会得到 108 /5 = 22 个排序文件。
- 第二轮:buffer pools 的5个页4个页用作输入,1个页用作输出,从22个文件中选取4个做归并,最后得到 22 /4 =6个排序文件。
- 第三轮:同上 buffer pools 的5个页4个页用作输入,1个页用作输出,得到 6/4 = 2个文件。
- 第四轮:同上 得到一个有序文件。
-
有哪一些做 aggregation(聚集)的方案?
-
排序聚集
对于本身需要排序的例子(order by),先排序再去重。
-
哈希聚集
如果不需要排序(group by、distinct),再排序的话开销就会很大,这时候我们可以选择哈希聚集。
外部哈希聚集(external hash agg)主要分为两部:
- Partition:通过 HASH$_1$,我们用1个把数据输出到磁盘
- ReHash
-
-
join算法有哪些?以下述例子分析复杂的:
-
M pages in table R (Outer Table), m tuples total
-
N pages in table S (Inner Table), n tuples total
-
Nested Loop Join
-
Simple Nested Loop Join (stupid)
把外表的每一个元组和内表的元组进行比对。
Cost:$M +(m×N)$
-
Block Nested Loop Join
利用 buffer pools 存储一个一个块扫描,假设buffer pools 容量为B
Cost:$M+(\lceil \frac{M}{B-2}\rceil×N)$
-
Index Nested Loop Join
利用B+Tree索引
Cost:$M +(m×C)$ C是一个常数
-
-
Sort-Merge Join
先排序,再归并
排序复杂度可见上面的 (K-way) Merge Sort
- Sort Cost for Table R:$2M×(1+\lceil\log_{B-1}\lceil \frac {M}{B} \rceil\rceil)$
- Sort Cost for Table S:$2N×(1+\lceil\log_{B-1}\lceil \frac {N}{B} \rceil\rceil)$
- Merge Cost: $(M+N)$
Total Cost: Sort + Merge
-
Hash Join
把两个表数据做 Hash 然后存储到外部文件,再读取文件进行比对 join 连接。
- Partitioning Phase Cost: $2 × (M + N )$
- Probe Phase Cost: $(M + N )$
Total Cost: $3 × (M + N)$
-
-
有哪一些数据库执行模型?
-
Iterator Model
迭代器模型,又称为火山模型,每个关系函数都会调用自己的
next方法直到有数据元组返回(整个调用过程有点像栈,先进后出,直到叶子节点返回数据,再一路回到顶,像火山的流动一样)。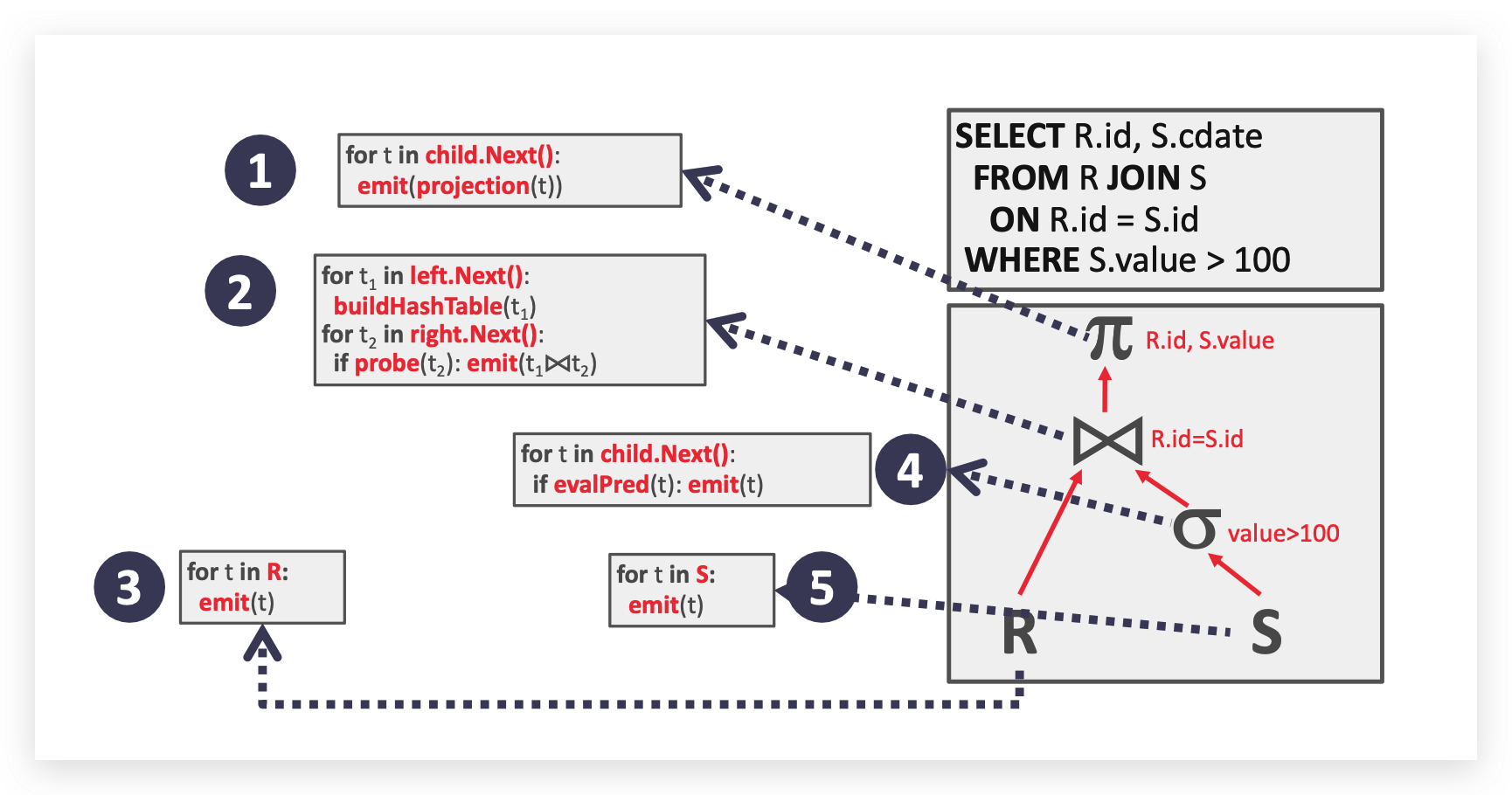
一些关系函数会堵塞,直到所有数据返回(比如 joins, subqueries, order by),也被称作 pipeline breakers.
-
Materialization Model
相比于火山模型流式的一条条返回和读取数据,物化模型会把所有数据全部打包好一次性返回。
-
Vectorization Model
向量化模型是以上两种模型的折中模型,其内部也实现了
next方法,但是每个next方法返回的是一批数据而不是单个元组,自定义数据大小也避免了物化模型中数据量返回过大的可能。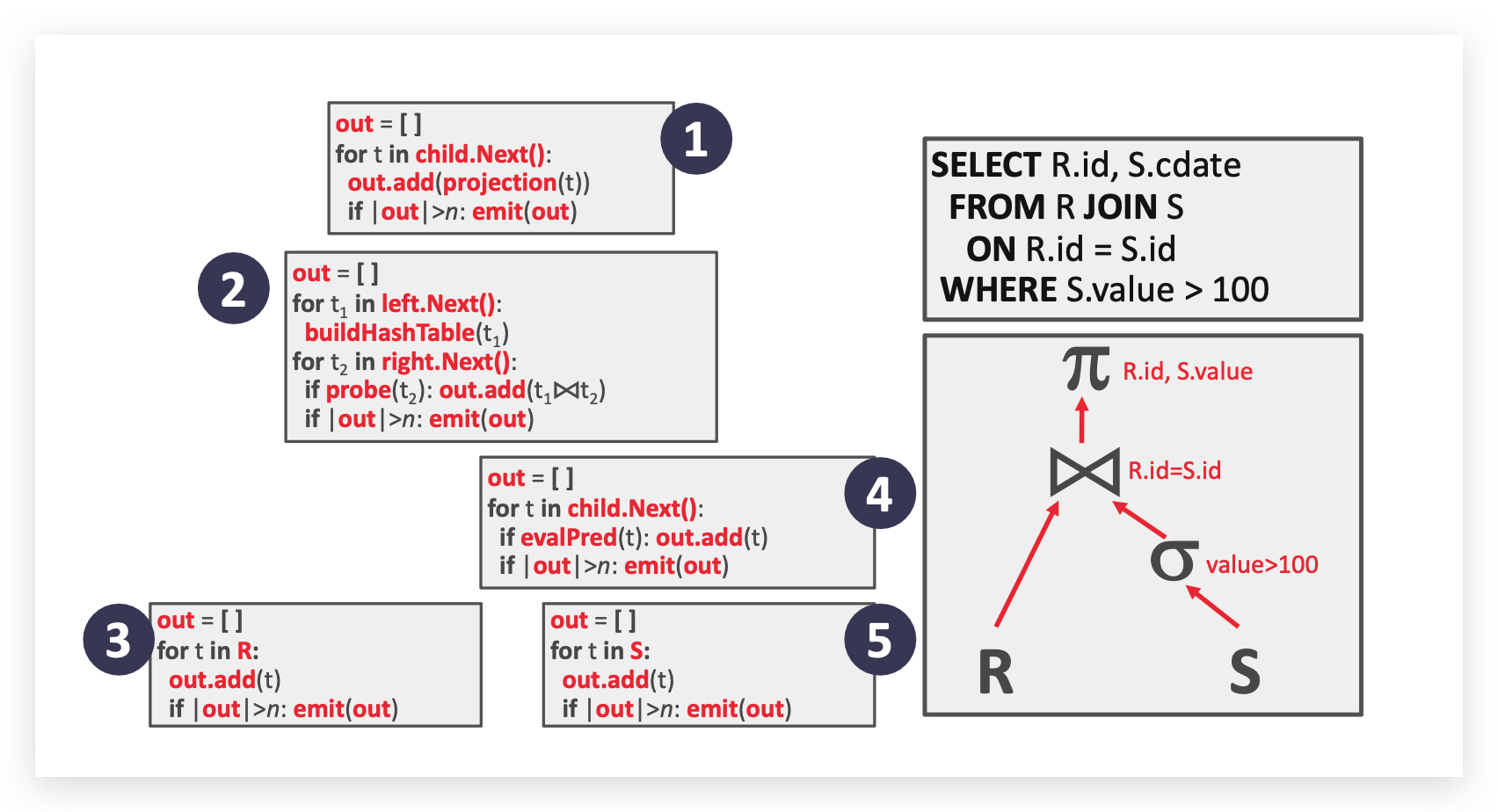
-
-
有哪一些数据读取的方法?
-
Sequential Scan
顺序扫描,或者说全表扫描。数据库维护一个扫描当前页的指针,顺序扫描有以下优化方法:
-
Prefetching
-
Buffer Pool Bypass
上面两种方法都是站在缓存池的角度,具体可以看
6. buffer pool 可以做哪些优化? -
Parallelization
-
Zone Map
维护一个额外的分区表去缓存页信息,可以降低扫描时读取页面的总次数。
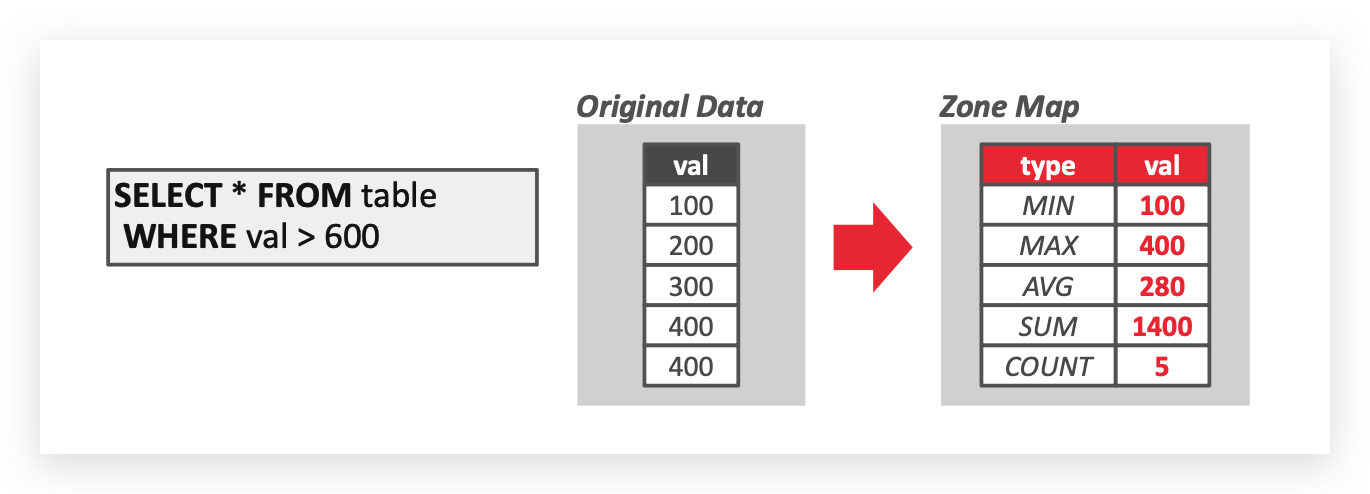
-
Late Materialization
延迟物化,即数据传递中,自底向上只传入一个关键信息(比如关键字段、偏移量等),需要用到具体数据时再获取全部的信息。此方法只在 DSM(列存储)中有效。
-
-
Index Scan
优化器选择最合适的索引去扫描(该索引的选择率最高)。
还有一种方式是采用 bitmap 多索引扫描,再根据具体语句选择交集或者并集。
-
-
单个 Intra-Query 如何做并行?
-
Intra-Operator Parallelism (Horizontal)
算子内并行(水平切分),指把单个数据集拆分为多个单位,然后在数据子集上执行相同的函数,最后再利用
Exchange操作进行合并。 -
Inter-Operator Parallelism (Vertical)
算子间并行(垂直切分),有一点像火山模型中的流式处理,
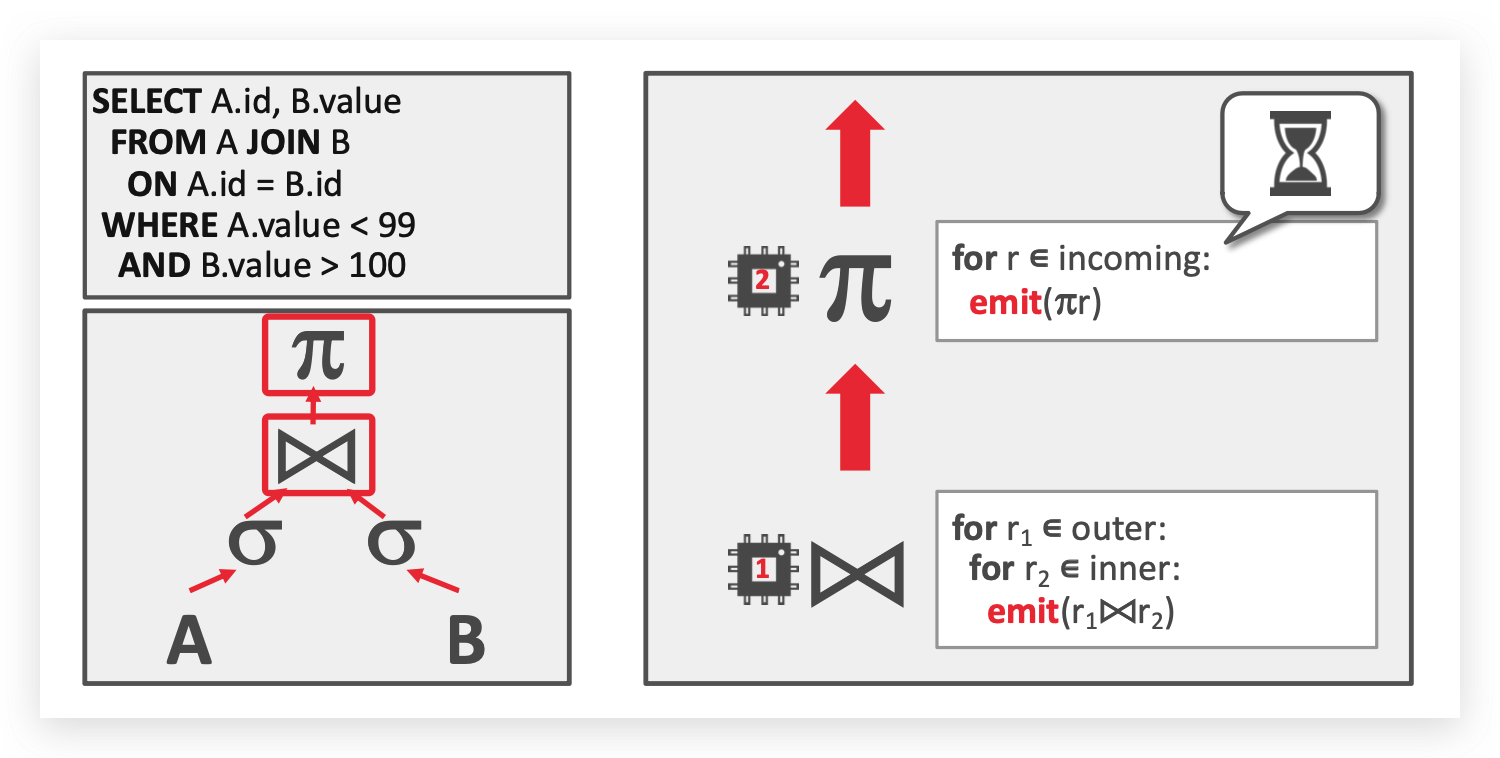
-
Bushy Parallelism
相当于水平切分+垂直切分,底层数据读取使用水平切分,数据往上传递使用垂直切分。
-
-
谈一谈数据库执行的逻辑优化和物理优化?
逻辑优化是站在代数级别的,通常是通过一些静态规则和启发函数(heuristics),在代数等价的前提下对表达式进行优化,比如谓词下放、投影下放等优化。
物理优化是站在开销的角度,这个开销可以指多方面,比如 CPU、Disk I/O、Memory、Network,然后在执行层进行等价优化,比如单个 join连接 有多种算法,单个数据读取有索引读取和全表读取,优化器就会根据具体的开销决定执行哪一种算法。最后再用动态规划确定整个执行的所有方式,如果需要 join 的表很多,动态规划的开销本身也很大,可以选择遗传算法的思想确定。
-
简单介绍一下ACID?
- Atomicity:原子性,即事务中的所有操作要么全部执行,要不都不执行,原子性通常通过 Logging 的方式保证。
- Consistency:一致性,站在一个 high - level 的角度,事务执行前后的逻辑都是正确的。
- Isolation:隔离性,虽然事务是并行运行的,但是对站在单个事务的视角其互不影响,其通过并发控制保证。
- Durability:持久性,所有事务提交的数据不会丢失。
-
如何判断事务的执行顺序(schedule)是否与其串行执行(serial)等价?
如果 schedule 只有两个事务,可以交换事务间的非冲突操作(冲突指读写冲突、 写写冲突等),如果最终可以转换到 serial schedule(即一个事务的所有操作结束完再执行另外一个,而不是 interleave ),则说明这个 schedule 是可串行的(serializable)。
如果 schedule 包含多个事务,可以用依赖图判断,如果一个来自事务 A 的操作和来自事务 B 的操作冲突,并且 A 先于 B 执行,则我们加一条从 A -> B 的边,以此遍历,若最后依赖图有环,则说明此 schedule unserializable;若最后依赖图无环,则根据箭头顺序,可构造 serial schedule。
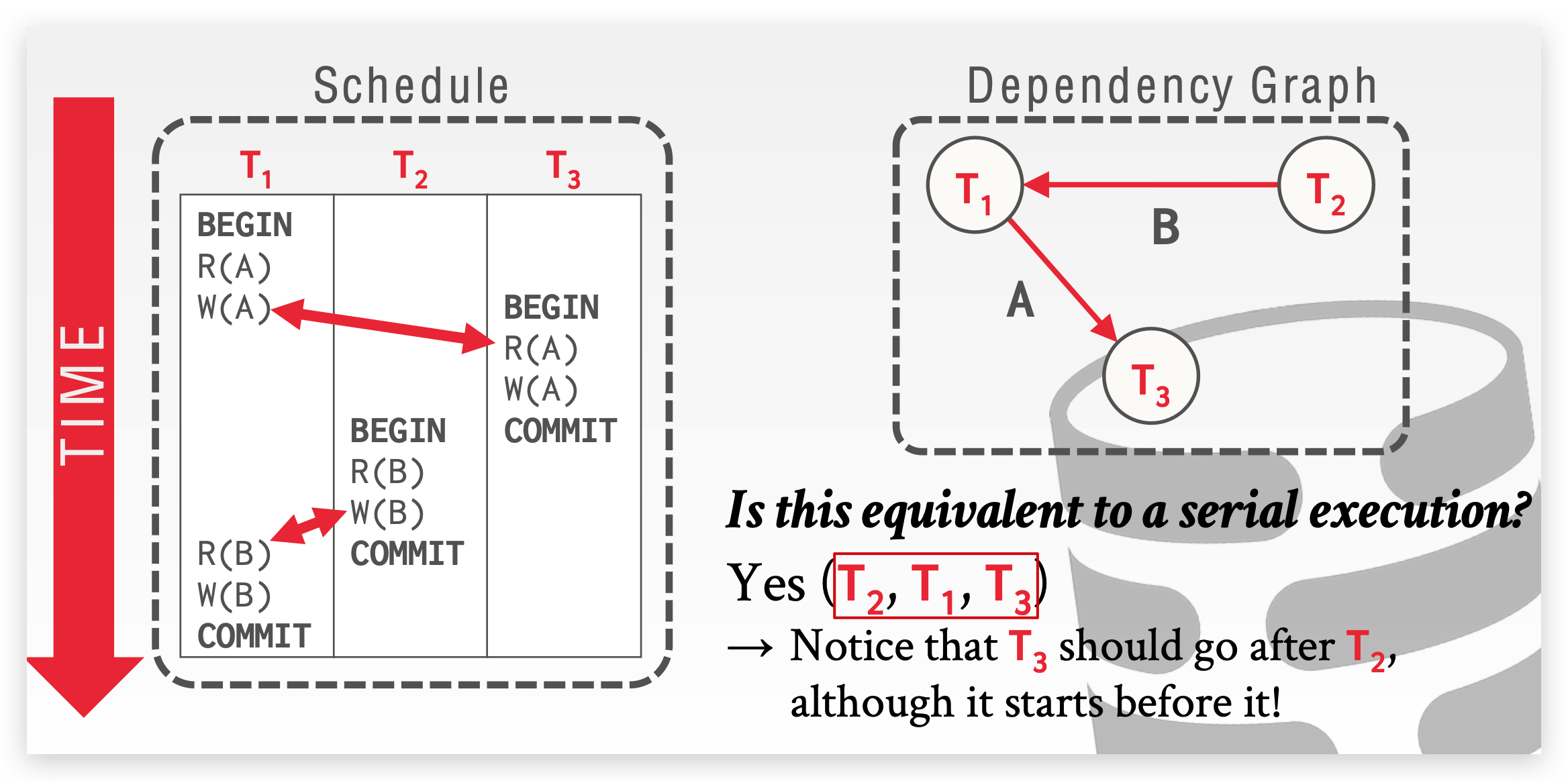
-
什么是 View Serializability?
上述我们判断是否可串行化,是通过冲突判断的,但是这样有弊端,因为有的事务具体的执行之间即使发生冲突,也不会影响最终结果,我们认为这两者还是可以调度的,这是基于观察的判断,比基于冲突更加缓和一些。这是一种理想化的判断,可以作为是否可串行化的标准,但是很难实现。
-
什么是两阶段锁?如何解决集联中止和死锁的问题?
两段锁协议 2PL(two-Parse-locking)指一个事务分为 Growing 和 Shrinking 两个阶段,第一个阶段事务所有操作申请锁,从一个锁释放开始进入第二个阶段,事务只能释放锁不能再申请。2PL 解决了一致性的问题(某个事物对多个变量操作,不会被其他事务所 interleave):
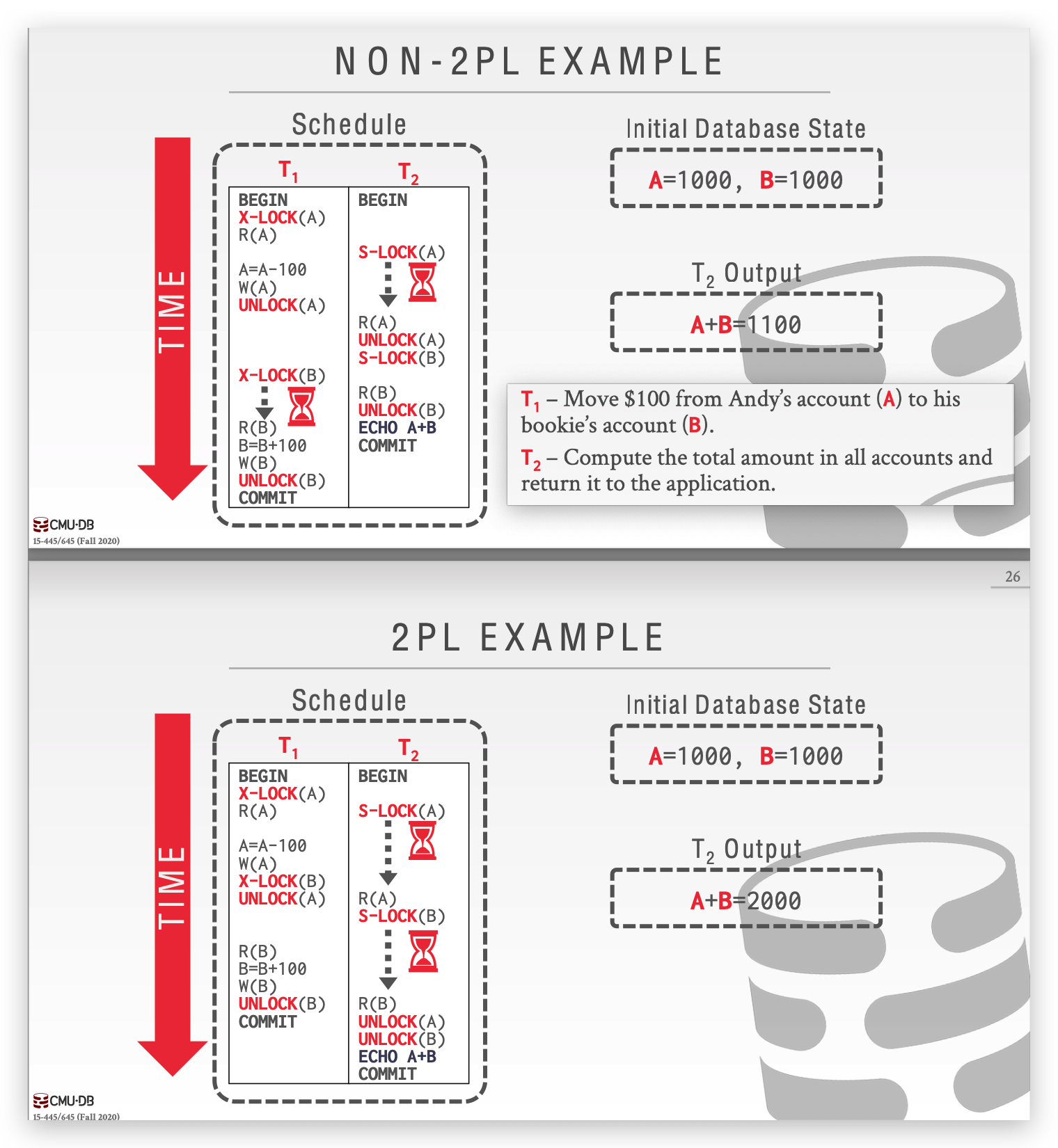
但是 2PL 还是有两个问题需要解决,一个是 cascading aborts ,如果事务 T2 读取了事务 T1 的某个中间状态,但是事务 T1 最后没有 commit 而是 abort,那么事务 T2 也应该回滚。解决的办法是采用 Strong Strict 2PL,即事务只有在最后时刻(commit、abort)才会一同释放锁,这是一种更加悲观的决定,也限制了并发。
还有一个问题就是死锁,上面这张图中的 T2 事务,如果先申请 B 的锁再申请 A,就会导致 T1 申请 B时被锁住,导致死锁。
站在死锁检测(Detection)的角度,我们创建一个锁依赖图,如果存在 T1 事务申请锁被 T2 事务堵塞的情况,则绘制一条从 T1 到 T2 的边,如果依赖图成环,则表明存在死锁,我们需要选取一名 victim 事务,对它进行 abort 或者 recommit,以打破死锁。victim 的选择需要考虑多方面,比如已经开始的时间、已经执行的操作、多少事务需要被回滚等等。
死锁检测是已经发生死锁后再进行处理,死锁预防(Prevention)是在死锁发生前 kill 一个事务,我们给事务定义一个优先级,在这里我们认为决定因素是起始时间,开始早的为 old,晚的为 young
-
Wait-Die (“Old Waits for Young”):如果是新事务占有,老事务申请,则选择等待;反之老事务占有,新事务申请,则新事物直接 abort 。(碰瓷)
-
Wound-Wait (“Young Waits for Old”):如果是新事物占有,老事务申请,则新事物直接 abort,老事务占有锁(抢过来),反之选择等待。
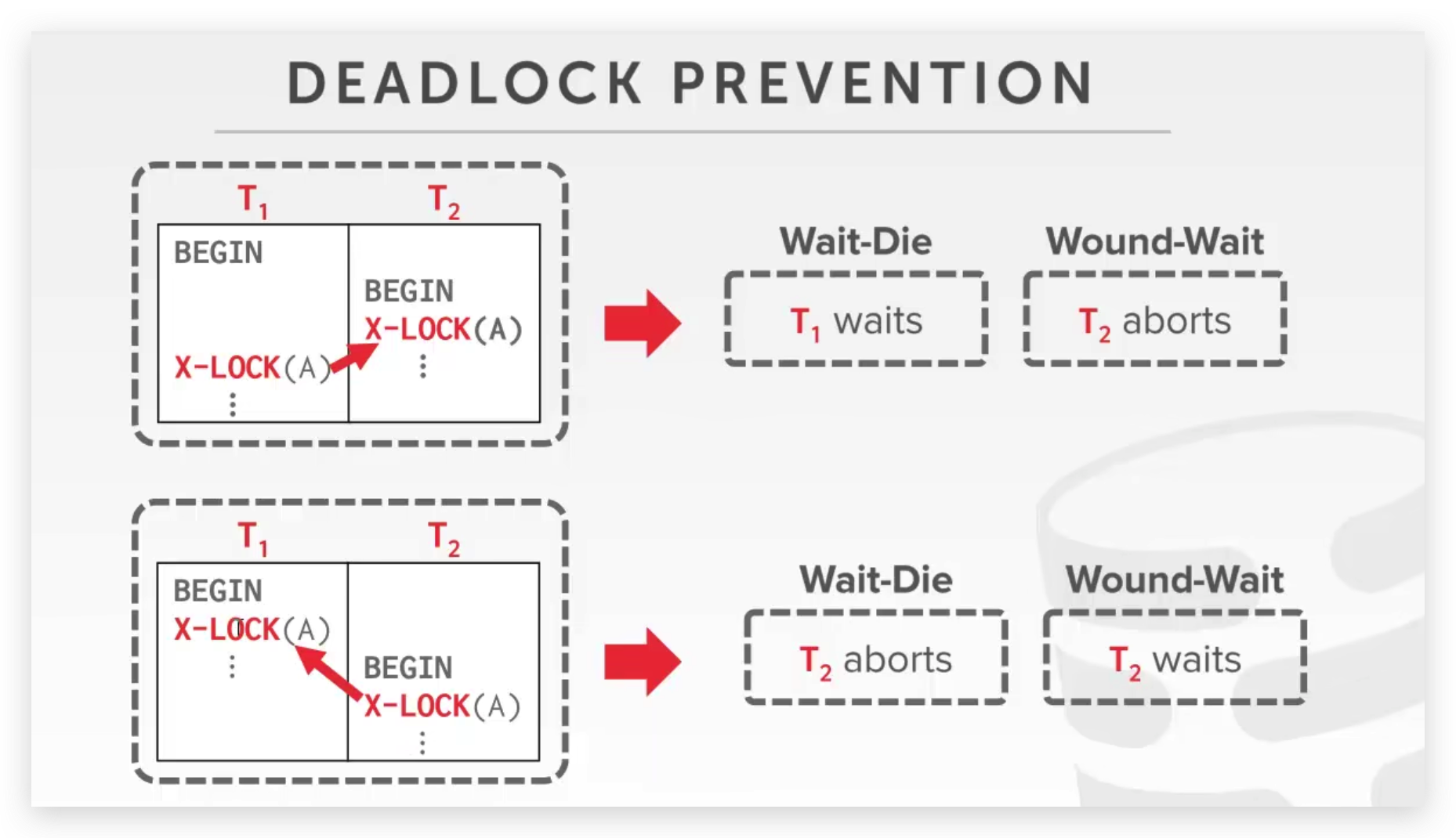
还需要注意一点,一个事务如果 abort,begin 时间应该不能改变,不然很有可能导致饥饿。
-
-
什么是 LOCK GRANULARITIES ,为什么要这么设计?
假设一个表有 100 行数据,我们需要更新里面所有的数据,我们可能需要 100 把锁。所以我们需要引入锁的粒度,也叫 Hierarchical locks(分层锁协议)。 锁可以是面向 Page 的,也可以是面向 Table,再往小还有 Tuple,如果我们往低级别上锁的同时,也给高级别一个标记,可以减少实际的锁用量,这里引入意向锁的概念:
- Intention-Shared (IS):将给下面低级别上 S 锁。
- Intention-Exclusive (IX):将给下面低级别上 X 锁。
- Shared+Intention-Exclusive (SIX):将给下面低级别上 X 锁,并自身上 S 锁。
我们以下面这个例子为例:
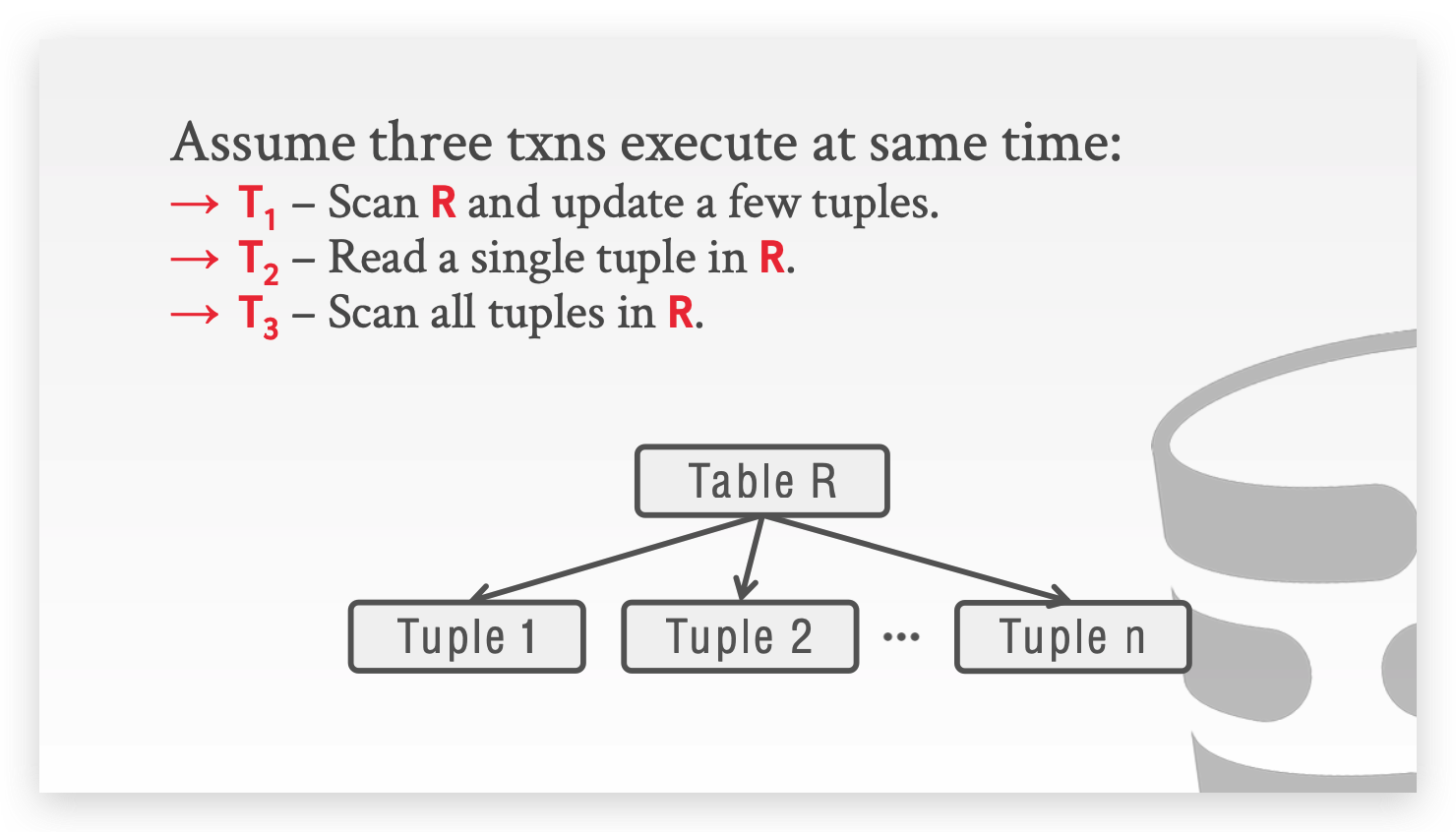
T1:扫描 R 并更新几个 Tuple ,我们需要给 Table R 上 SIX 锁,并给更新的Tuple 上 X 锁。
T2:从 R 中读取一个 Tuple ,给Table R 上 IS 锁,并给读取的 Tuple 上 S 锁。
T3:扫描 R,需要给 R 上 S 锁,和之前的 SIX 冲突,被堵塞。
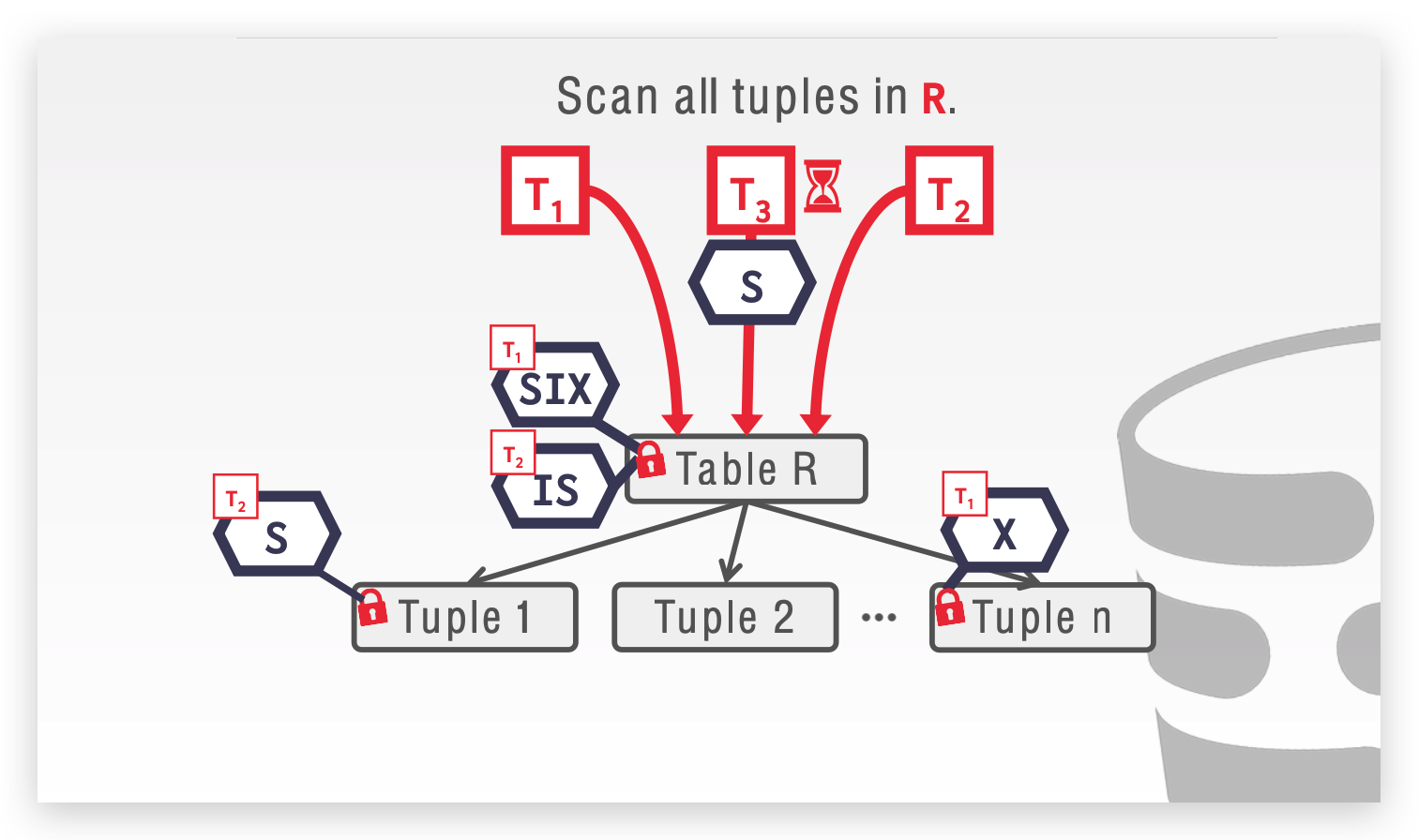
还有一个问题,我们需要去设计一个这个颗粒度,比如我们读取多个 Tuple,并不是只有读取全部才上 S 锁,从 IS 到 S 有一个自适应的升级过程,需要我们去权衡。
-
如何基于时间戳进行并发控制?
比较基础的方式是 Timestamp Ordering (T/O),每一个事务 $T_i$ 有一个起始时间戳 $TS(T_i)$ ,若 $ TS(T_i)<TS(T_j)$ ,则说明 $T_i$ 的执行顺序应在 $T_j$ 之前。
对于每一个数据库 item 都全局使用 $R-TS(X)$ 和 $W-TS(X)$ 记录上一次被读、写的时间戳。
当事务需要读写 item 时,就会去检查上面的这个时间戳,如果发现是将
- 读取一个未来已写的 item
- 修改一个未来已读或写的 item
则选择 abort 该事务,并设置新的 timestamp。
可以看到 T/O 是一种乐观的事务模型,并没有使用锁机制。但是如果存在某个长事务,会不断被后面的一些短事务中止,有可能出现饥饿的情况。
如果我确定所有的事务都很短并且冲突较少,Optimistic Concurrency Control(OCC)也是一种很好的乐观处理方式,OCC 中每个事务都有一个私有的属性表,用于暂存读写的内容,并在 Validation Phase 阶段判断是否 abort,通过则把私有表刷新到数据库。( OCC 是最后一起判断是否通过,所以长事务更加容易饥饿)
-
并行事务可能出现怎样的问题?事务有哪几种隔离级别,有什么特点及其实现?
从上往下对一致性的影响依次减轻:
- Dirty Read(脏读):读取到了其他事务还未提交的数据。
- Unrepeatable Reads(不可重复读):一个事务前后读取到的数据不一致。
- Phantom Reads(幻读):一个事务前后读取的记录数量不一致。幻读和不可重复读的区别在于后者通常是 update 导致,前者为在两次顺序遍历时 insert or delete 导致前后不一致。
四种隔离级别,从上往下隔离级别递增,性能效率递减:
- READ-UNCOMMITTED(读未提交):一个事务还未提交,它所做的变更就会变其他事物看到。上面三种问题都有可能发生。
- READ - COMMITTED(读提交):一个事务提交之后,它所做的变更才能被其他事物所看到。解决了脏读的问题。
- REPEATABLE READS(可重复读):一个事务在启动到结束中看到的数据都是一致的。解决了不可重复读的问题。
- SERIALIZABLE(可串行化):这个我们已经了解很多了,serializable 通常通过 Strong Strict 2PL 实现。
-
MVCC 设计需要考虑哪几个方面?
MVCC (Multi- Version Concurrency Control)的核心思想为读写互不堵塞,一共需要考虑以下四个方面:
-
Concurrency Control Protocol
选取一种并发控制协议,也就是我们前面所谈到的 2PL、T/O、OCC 等。
-
Version Storage
DBMS 为每个 tuple 维护了一个全局属性表, tuple 不同版本之间通过链表连接起来,根据存储逻辑的不同也分为三种:
- Append-Only Storage:全部 tuple 存储到一个表空间内。
- Time - Travel Storage:用一个 单独的 time-travel 表维护老版本的 tuple。
- Delta Storage:和前者类似,不过表内只维护变化的数据,而不是整个列数据。
-
Garbage Collection
那些用不上的旧版本属性,我们需要垃圾回收,GC可以站在 tuple 的角度,一些线程定时扫描整个 table,寻找可回收的旧版本;或者站在事务的角度,事务自身决定哪些 tuple 需要被回收。
-
Index Management 我们可以通过索引查询数据,所以索引也是需要链接到多版本的。
-
-
能否不使用 LOG 实现 undo 和 redo?
- 撤销(Undo):未完成或者由于各种原因发生回滚(rollback)、中断(abort)的事务,其修改需要被撤销,即回滚为事务之前的旧值。
- 重做(Redo):已经提交的事务,其修改操作的效果需要体现为新值。
SHADOW PAGING 对 database 有 master 和 shadow 两份拷贝,更新只改变 shadow 拷贝的部分,当提交时只需要改变 DB Root 的指向,把 shadow Page 刷盘并 GC 之前的 master。如果 undo 则不需要做任何更改。缺陷是在内存中拷贝一份复制代价太大。
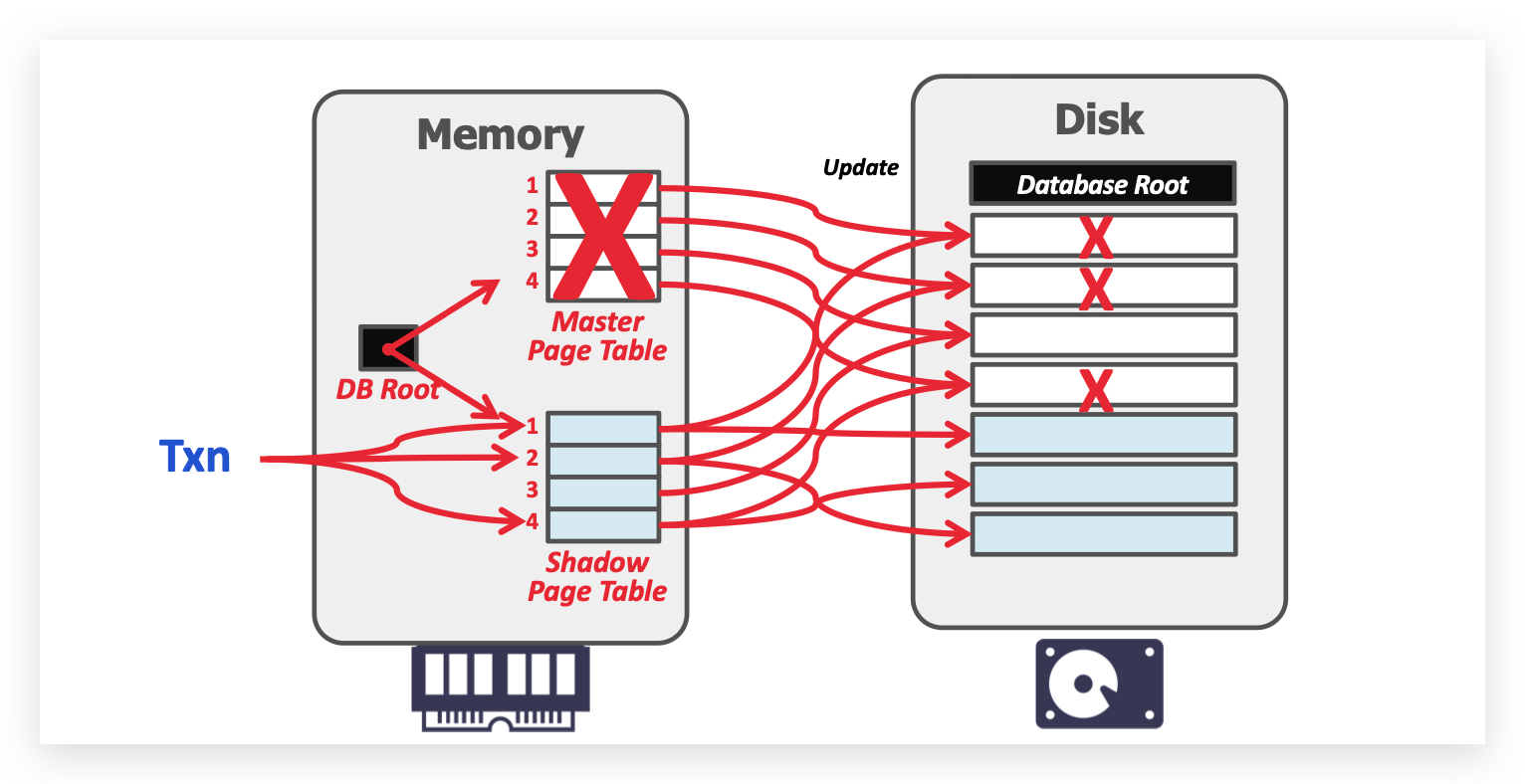
-
什么是 WAL?
WAL 即(Write-Ahead Logging),是现在主流的备份形式。在事务提交前所有操作都会被记录到 WAL,主要包括事务ID、Object ID、Before Value(用来 UNDO)、After Value(用来REDO)。
WAL的记录格式分为三种:
- Physical Logging:记录具体的页偏移位置的变化。
- Logical Logging:直接记录事务层的操作语句。
- Physiological Logging:混合上面两种,只记录页的某个 slot 的变化。
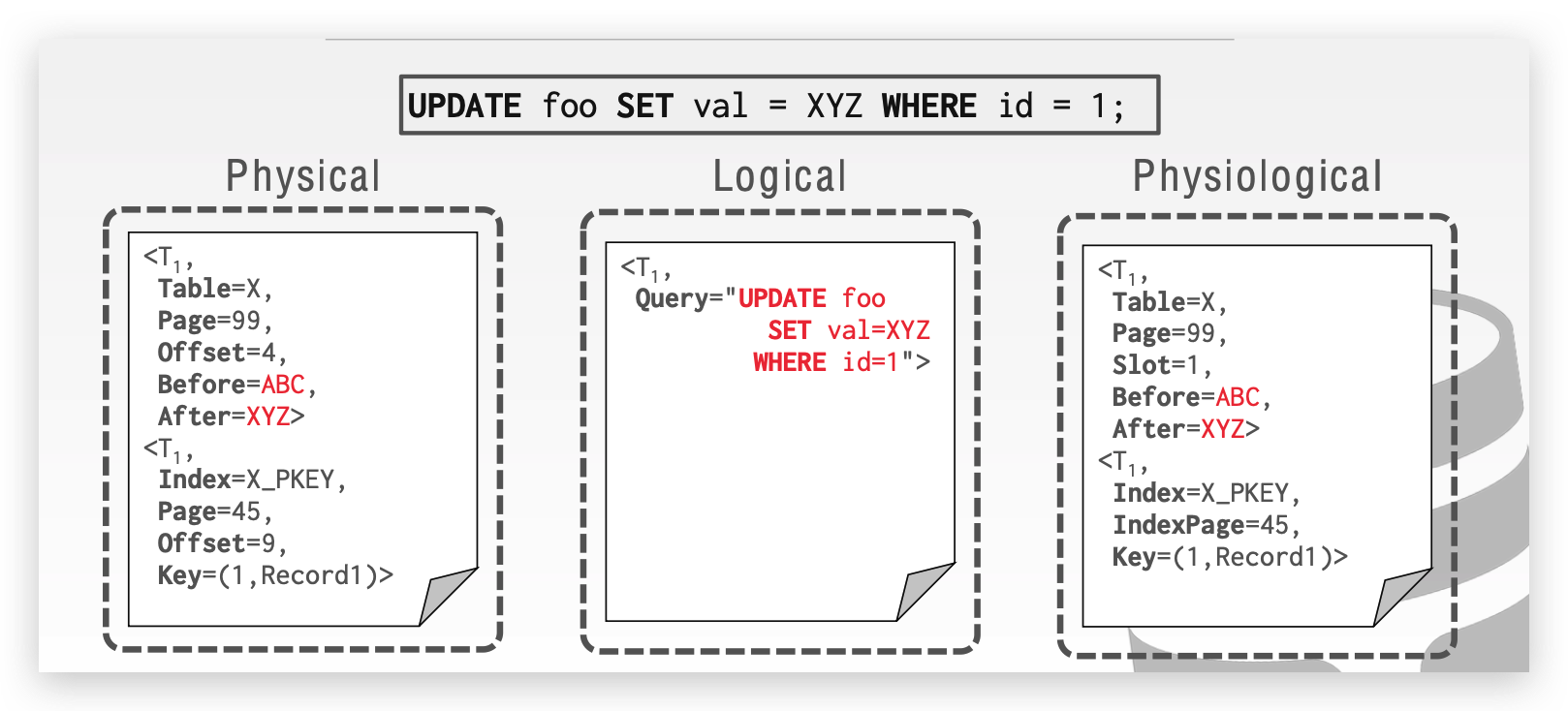
随着 WAL LOG的增大,DBMS 会定时给 WAL 写入 Checkpoints(类似游戏中的存档点),在 checkpoints 之前的日志如果已经 commit,我们可以确保已经写入磁盘,则可以把这部分内容清除。
后续一部分关于分布式数据库的知识,打算有时间结合 6.824 一起学习。