前言
第二个实验需要我们实现一个磁盘支持的可拓展哈希表,哈希表只负责快速搜索,不必大规模遍历表内的每一条记录。(后者用 B+ Tree 索引更加合适,20 年的实验实现的就是这个,感兴趣也可以做一做)。
我们先跟着 geeksforgeeks 这个网址,快速过一遍可拓展哈希表的实现。
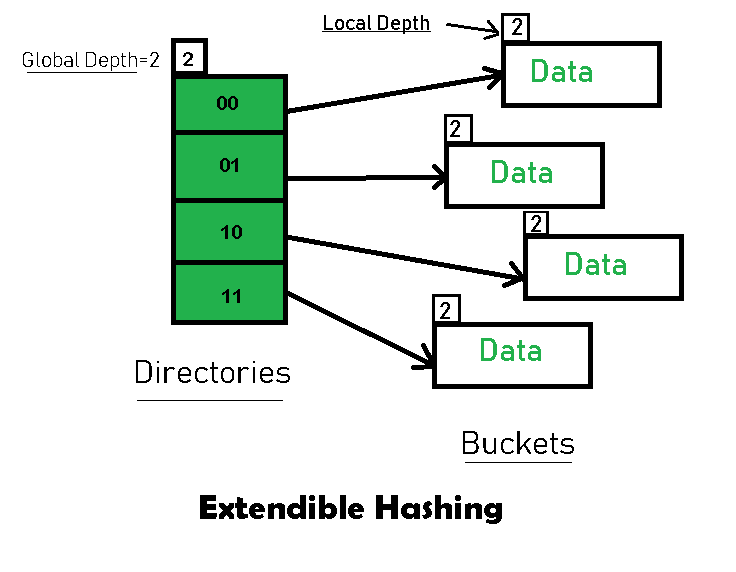
在上述示意图中,一共设计以下 4 种属性:
- Directories:目录,你可以理解为一个数组,其中每一个元素存储一个指向 bucket 的指针,bucket 本身也是一个页,所以只需要存储
page_id即可。 - Buckets:存取 key 和 value ,一个 bucket 可以存取多个键值对。
- Global Depth:整个 directories 维护了一个全局的 global depth,针对一个被 hash 后的 key,比如
5 = 00...00101,意味着这个结果的后 global depth 位有效(我们默认使用 LSB Least Significant Bit:最低有效位),在上图中 global depth = 2 表示 5 将落在 01 所对应的 bucket 上。你也可以发现任意时刻 directory 的数目 =2^global_depth,但这并不意味着 bucket 的数目,因为还有一个 Local Depth。 - Local Depth 是针对每一个 bucket 而言,自身维护的深度,任何时刻 Local Depth 的大小总 ≤ Global Depth ,这个我们会在后面提到。
一个 bucket 可以维护的数据大小由具体情况而定,这里我们假定为 3 ,然后 hash 算法就用 int 的二进制表示,我们通过以下的例子理解:
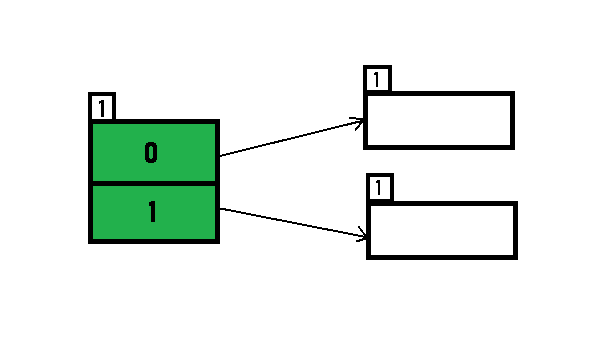
假设初始的 directories 和 buckets 状态如下,
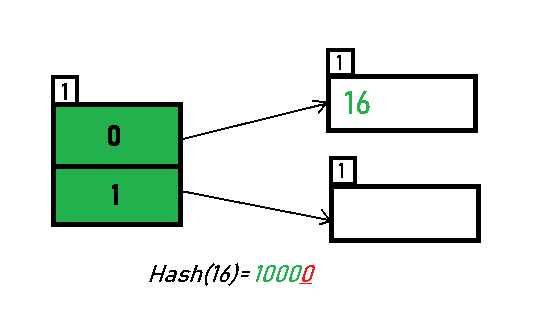
这时候插入数据 16(10000),global_depth 为 1,所以它会落在 bucket_index = 0 的 bucket 上。
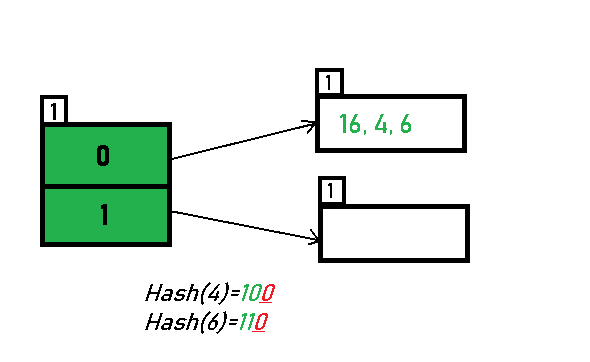
后续同理插入 4(100) 和 6(110) :
我们再插入22 (10110),这时候 bucket 容量已满,我们需要对 0 号 bucket 进行分裂,但是此时 0号 bucket 的local_depth = global_depth,所以我们需要先对 global_depth 也就是 directories 进行扩容:
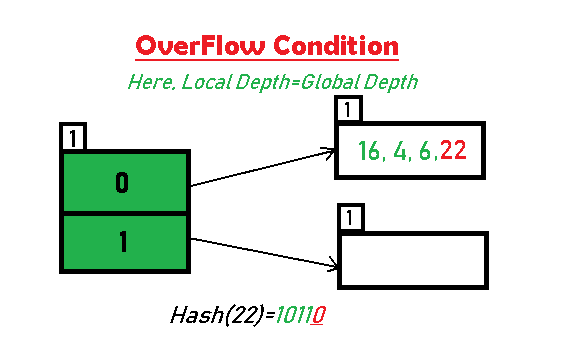
扩容第一步也就是 global_depth++,这时候上述 directories 包含 00、01、10、11,然后需要进行一步 rehash:每一个扩容前的 bucket 都需要找到它的 brother_bucket(即不算新的一位后续完全一致),然后重新排列内部的数据
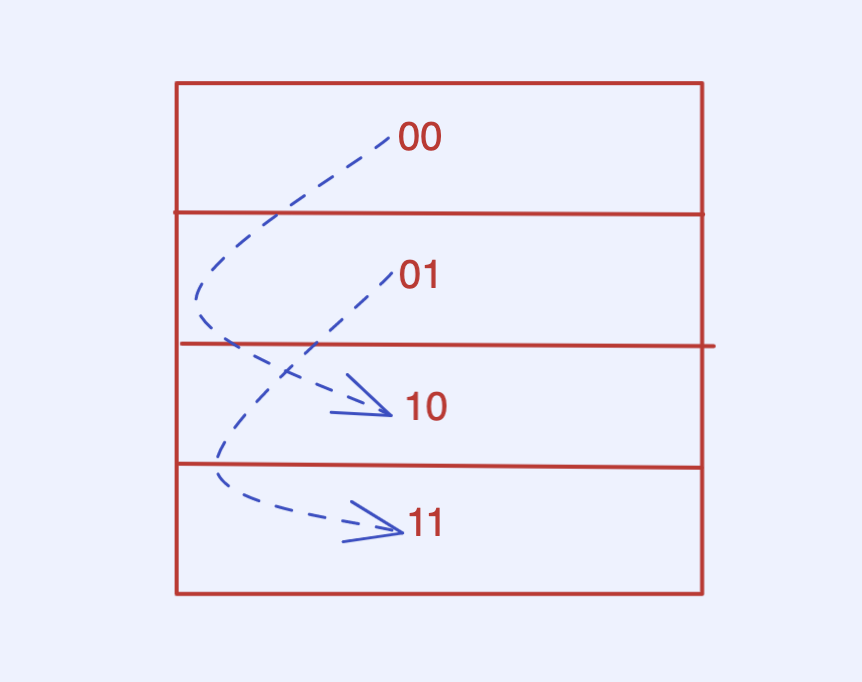
之后再选择插入 22(10110)
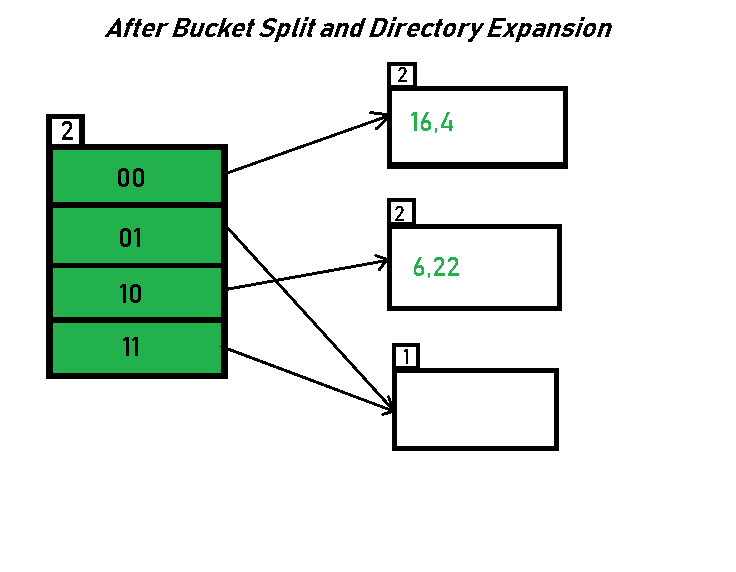
针对以上的例子,我们有三个需要注意的地方:
-
任何时刻,所有的 local_depth ≤ global_depth
-
每个 bucket 有
2^(global_depth-local_depth)数目个索引指向它:这个其实比较好理解,因为目录扩容时,没有发生 split 的 bucket 将保持不变,索引也会翻倍,split 时索引会减半,这会导致不同local_depth 的 bucket 索引不同 。
-
指向同一个 bucket 的 local_depth 相同:
local_depth 并不是 bucket 自身的成员属性,而是在 directories 内的一个
local_depths_[bucket_index]数组,所以我们在 split 和 merge 操作时需要注意。
在这个教程中没有介绍 remove 和 merge,我也就随便画个草图:
同样是上述例子,假设我们 把 6、22 都删除后,变为:
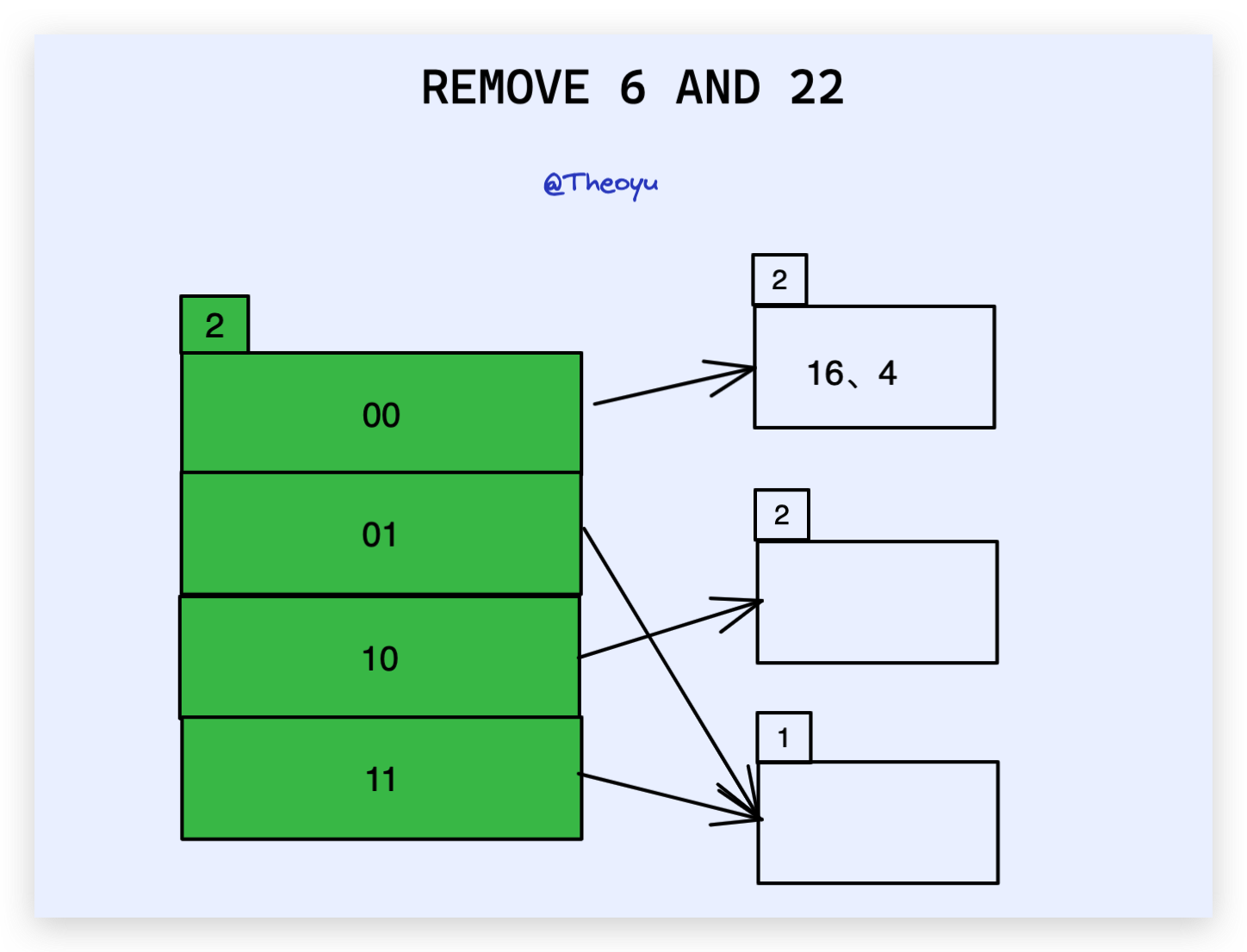
此时 01 所对应的 bucket 为空,我们需要进行 merge 操作。
merge 其实很简单,就是当 remove 之后,发现该 bucket 为空,则删除这个 bucket 页,并在 directories 中把所有指向该 bucket 的 索引 指向它的 brother_bucket ,并修改 local_depth 。
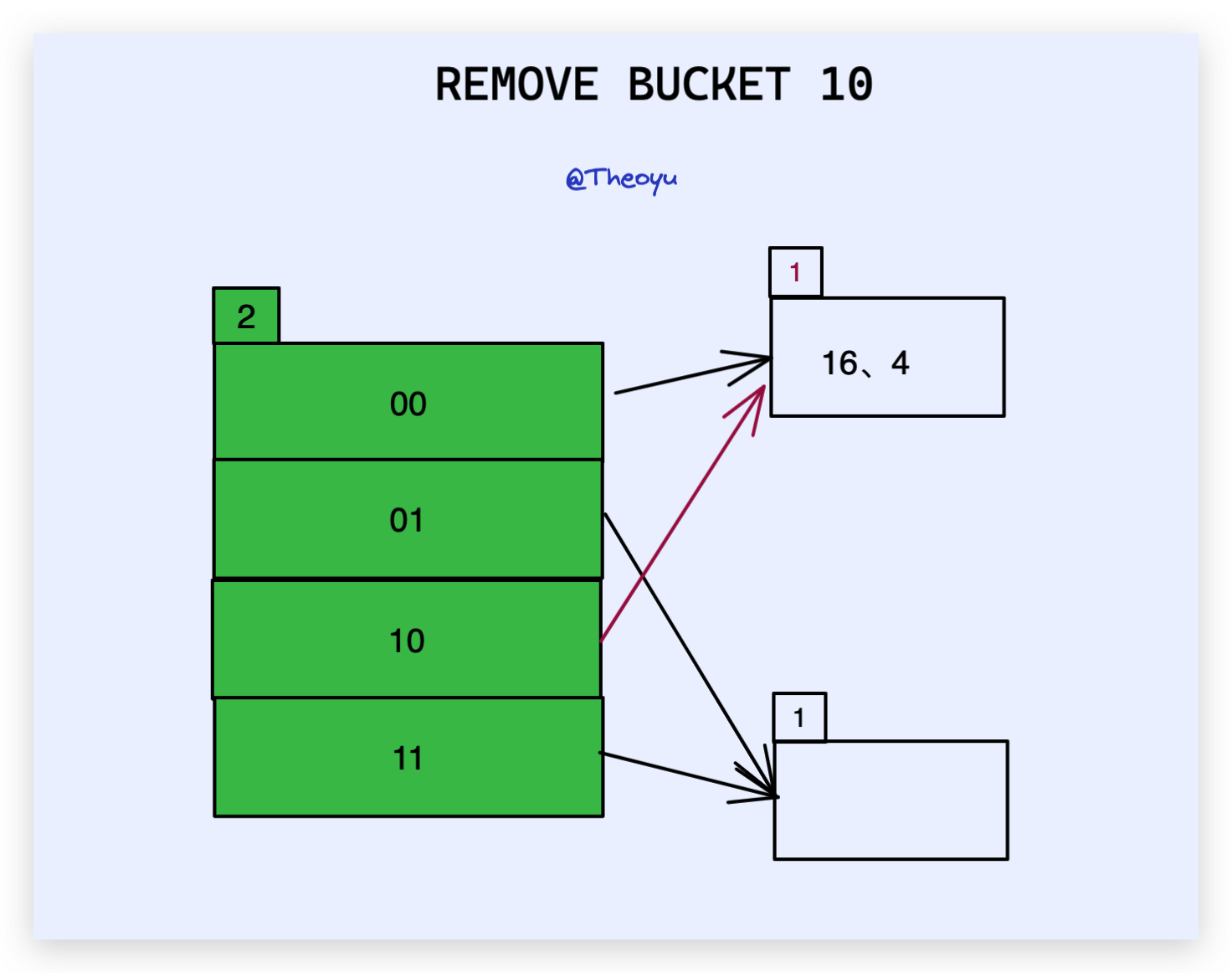
这里我们发现所有的 local_depth < global_depth ,换句话来说就是每一个 bucket 都至少有两个索引指向它,并且这多个索引对是 互为 brother 的关系,我们就可以直接 global_depth--,全局收缩 directories 。
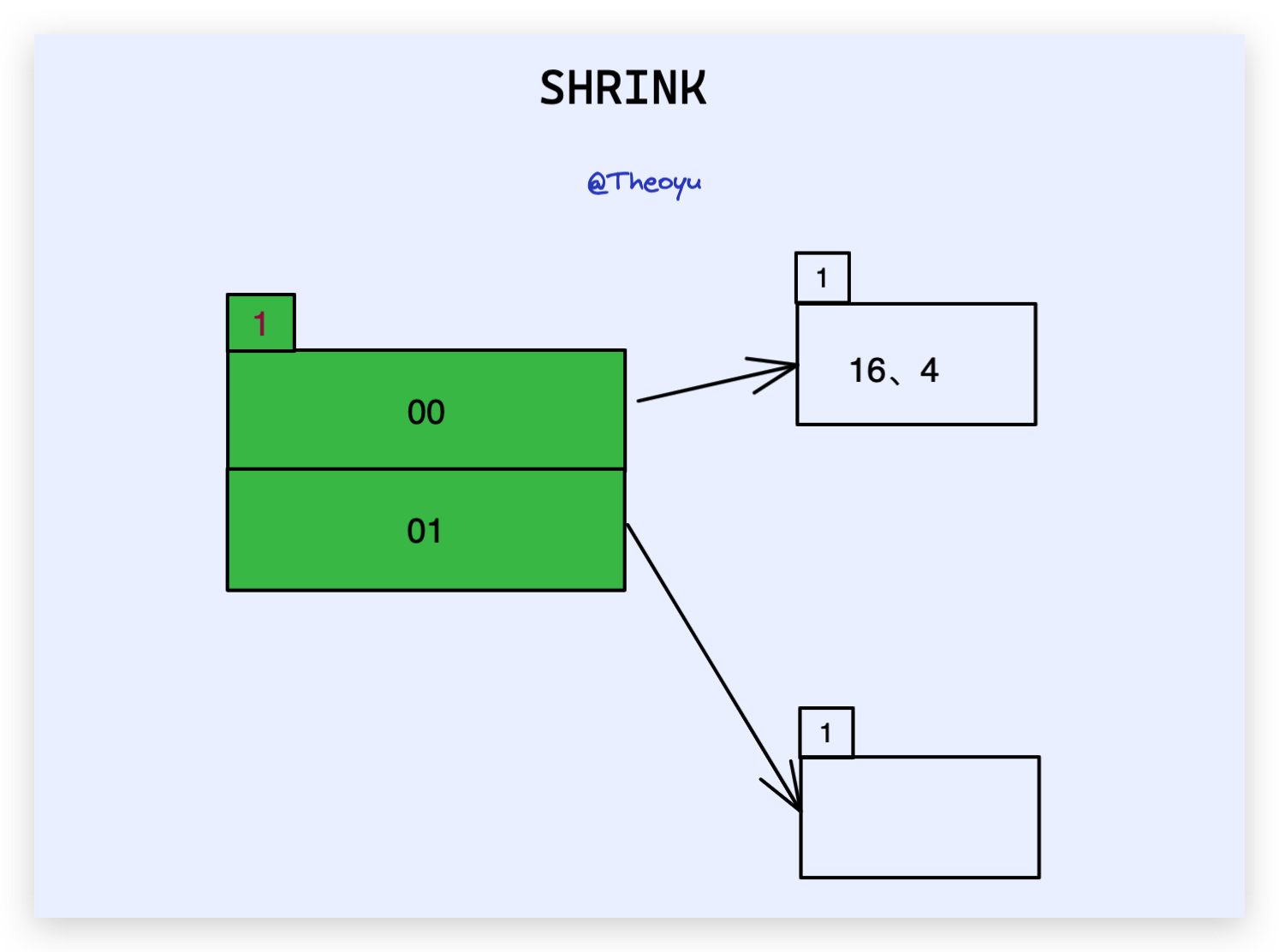
相当于回到了扩容前的状态。
有了以上基础,我们完成 project 就会简单很多。
TASK #1 - PAGE LAYOUTS
这一部分,需要我们完成 directories 和 bucket 的内部实现。
思路
我们先看看 directories 的内部成员变量:
- page_id_ :directories 的页 id
- lsn_:暂时还没能用上
- global_depth_:全局 bucket 深度
- local_depths_[bucket_index]:每个 bucket 的深度
- bucket_page_ids_[bucket_index]:每个 bucket 的page_id
directories 需要实现的方法没什么好说的,根据注释一步一步写就行了,如果你对 split 不太了解可能会对 GetSplitImageIndex 这个方法感到奇怪,这个其实就是上面我们所说的去一个 bucket 的 brother_bucket,也可以先空着,后面具体实现再补上。
再来看看 bucket 的成员变量:
char occupied_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1];
char readable_[(BUCKET_ARRAY_SIZE - 1) / 8 + 1];
MappingType array_[1];
occupied_ 和 readable_ 都是 char 数组,一个 char类型占一个字节,也就是8位,从00000000->11111111,所以对于任何一个 bucket_index,我们只需要用 bucket_index / 8 判断在哪一个数组内,再用 bucket_index % 8 判断在8位中的哪一位即可。
其中 readable_ 表示某一位是否有元素占用,occupied_ 表示某一位是否有过元素占用,简单来说就是经过 remove,前者将变为 0 而后者仍为 1,知乎上有讨论 occupied_ 的实际作用,其实在 bucket 有一个 PrintBucket() 用于打印当前 bucket 的状态,里面就用到了 occupied_ ,所以我能给出的唯一解释可能也只是用作调试分析吧。
最后的 array_[1] 是一个变长数组,用于存储真正的 kv。
提示
在 directories 中有一个 VerifyIntegrity()方法,用于检测 所有 bucket 的状态是否正确,其注释为:
/**
* (1) All LD <= GD.
* (2) Each bucket has precisely 2^(GD - LD) pointers pointing to it.
* (3) The LD is the same at each index with the same bucket_page_id
*/
这三点我在前言中提到过,这个非常重要,我的大多半 bug 都是产生于此 XD。
TASK #2 - HASH TABLE IMPLEMENTATION
TASK #3 - CONCURRENCY CONTROL
TASK 2 是具体实现我们的可拓展哈希表,TASK 3是在 TASK 2 的基础上加锁,实现线程安全。我个人建议这两个 TASK 一起完成,因为重新 review 代码很容易漏掉一些考虑不全的点。
思路
首先确定一下,无论是 insert、remove 还是 getValue,步骤应该都是:
- 拿到 directory 的目录页。
- 通过 key 的 hash,找到具体的 bucket 页
- 对 bucket 进行操作。
怎么拿到页呢?其实就是通过我们 Project1 所实现的 buffer_pool_manager_ ,extend_hash_table 自身维护了一个 BufferPoolManager 私有成员,可通过 FetchPage 或 NewPage 拿到 Page。
拿到 Page 我们还需要进行一次类型转换,这里我们用 reinterpret_cast 强制类型转换,把 Page 转换为我们所需的 directory 或者 bucket 。注意每次我们使用完 directory 或者 bucket之后,记得 UnpinPage 。
剩下的内容其实就是对我们前言部分对完善,所以接下来着重说一下并发控制。
对可拓展哈希表而言,其私有成员ReaderWriterLatch table_latch_是一把读写锁,用于控制 directory 的线程安全;对于每一个 bucket 而言,其本身也是一个 Page (从获取来看我们也是先拿到 Page 再通过强制类型转换得到 bucket ),在 page.h 中我们可以看到每个 Page 也维护了一把读写锁 ReaderWriterLatch rwlatch_,所以我们所有并发控制都是通过这两把锁来考虑的。
Insert: directory 读锁、bucket 写锁。SplitInsert: directory 写锁、两个 bucket 都上写锁。(SplitInsert会设计 bucket 和 brother_bucket 两个桶)Remove: directory 读锁、bucket 写锁。-
Merge:directory 读锁、bucket 读锁 FetchDirectoryPage:这里我在 extend_hash_table 中加了一个锁成员,在directory_page_id_ == INVALID_PAGE_ID之前锁住,防止并发时 INVALID_PAGE_ID 的判断错误。
提示
在 merge 的官方注释上,有三点:
/**
* Optionally merges an empty bucket into it's pair. This is called by Remove,
* if Remove makes a bucket empty.
*
* There are three conditions under which we skip the merge:
* 1. The bucket is no longer empty.
* 2. The bucket has local depth 0.
* 3. The bucket's local depth doesn't match its split image's local depth.
*/
这个第一点很有意思,我们是在 bucket 为空的时候进入 merge ,然后在 merge 的同时还需要判断一次 bucket 是否为空,因为这里的锁并不是一直关上,两个方法调度时是有一个空档让其他线程执行的。
我在 debug 的时候发现多线程重复插入 500 个key,经常会出现多次 split 的情况(int 类型一个 bucket默认大小为496,按道理只会 split 一次),就是因为在进入 SplitInsert 我没有重新判断 bucket->IsFull(),当然这个由美每个人具体的写法而定,我也只是说一下我踩的坑hh。
最后
这个 project 最主要还是提高了我多线程并发的调试能力,合理运用 Log 定位到出问题的点。
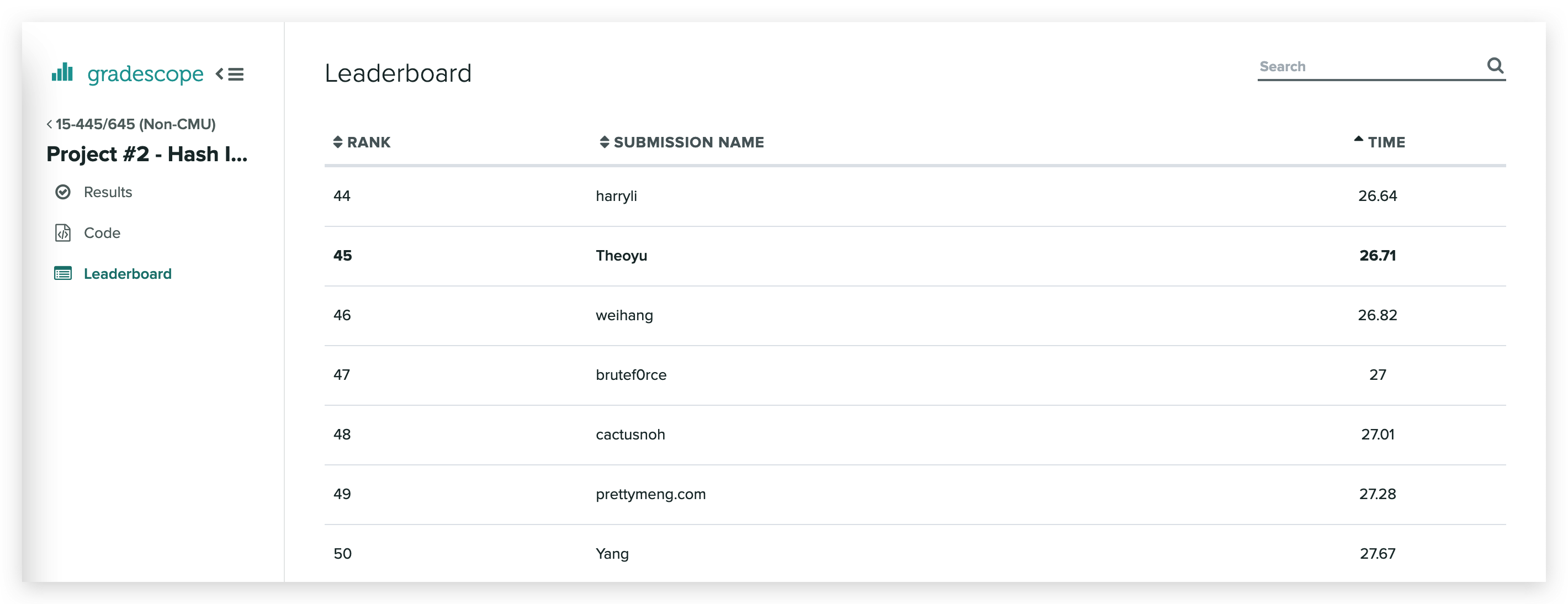
排名感觉还不错,另外前 20 名时间都在 1s 内,估计是把 test 给 bypass 了,面向测试用例编程 💤。