比特币
比特币中的密码学
哈希
hash的性质:
- collision resistance:哈希碰撞不是不会发生,是指很难以人为的方式去构造。
- hiding:哈希函数的计算过程是单向、不可逆的。
- puzzle friendly:hash计算的结果无法预测。
比特币中用到的哈希函数是 SHA-256(Secure Hash Algorithm)。
签名
去中心化的比特币系统中,由于没有第三方,所以需要『 签名 』明确交易的账户。
数字签名采用私钥进行签名,公布的公钥进行验证。
比特币中的数据结构
Hash pointer(哈希指针)
区块链结构本身是一条链表,节点为区块,链表通过指针指向的地址把节点所串连起来,在区块链中使用的哈希指针除了前一区块的地址,还包含前一区块的哈希。
genesis block A B most recent block
┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────┐
│ │ │ H() │ │ H() │ │ H() │
│ │◄──┤ │◄──┤ │◄──┤ │
│ │ │ │ │ │ │ │
└──────────┘ └──────────┘ └──────────┘ └──────────┘
如上图,每个区块都存有一个哈希值,哈希值的计算包括上一个区块内容本身+上一个区块的哈希,从而保证了内容不被篡改(tamper- evident log)。
比如如果破坏A的区块,则B存放的哈希值需要修改,最新的区块哈希值会计算B的哈希,从而也会修改,所以只要记住最后一个区块的地址,即可检测链上内容是否被篡改。
Merkle tree (默克尔树)
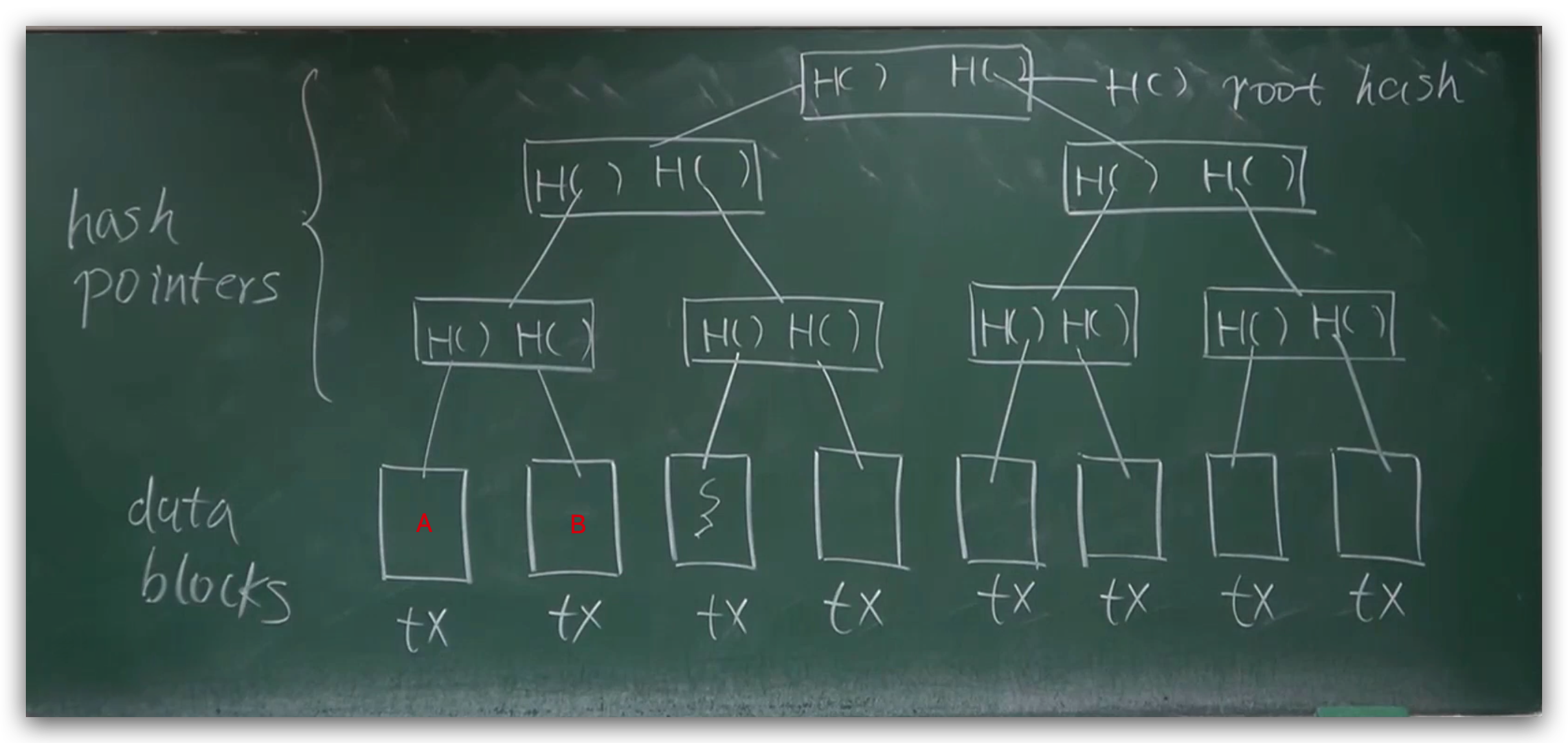
如图下方是数据块,上方是节点,默克尔树和二叉树的区别在于前者使用哈希指针代替普通指针,比如AB数据块的父节点就存有其二者的哈希,其父节点同理,所以只需要记住根哈希,便可以检测出对树中任何部位的修改。
对于区块链来说,不同区块通过哈希指针连接,每一个区块分为块头和块身,块身中存放交易列表,而由这个区块包含的交易,所组成的默克尔树的根哈希,就存放在块头中。
Merkle tree的具体用途:
比特币系统中,节点分为轻节点和全节点,轻节点只保存块头信息,而全节点保存区块所有内容。因为一个区块比较大,对硬件要求会比较高,比如像手机钱包,就会采用轻节点的方式存储。
当对一个轻节点证明某条交易(tx,transaction)是否被写入区块链时,便会用到 Merkle proof。我们把交易到到根节点这一条路径叫做Merkle proof ,如下图,当轻节点确认黄色交易是否属实时,会向全节点请求需要的哈希(下图红色哈希),然后自底向上进行计算,把得到的最终结果和根哈希进行比对,进而进行判断。

那这样是否是安全的呢?如果待验证交易是虚假的,是否可以再伪造一个红色哈希,来满足验证的需求,我们从哈希的三个性质来看,显然是不成立的。
Merkel proof 可以证明 Merkel tree中是否包含某个交易,所以这种证明又称为 proof of membership 或 proof of inclusion。 对于一个轻节点来说,验证一个 Merkel proof 的时间复杂度是多少呢?如果底层一共有 n 个交易,则时间复杂度为 $\theta(log(n)) $。
如何证明 Merkel tree 中不包含某个交易呢?即 proof of non- membership。可以把整颗树传给轻节点,轻节点收到后验证书的构造是对的,每一层用到的哈希值都是正确的,说明树中只有这些叶节点,如果不在这里面,则证明proof of non- membership。这样的时间复杂度为 $\theta (n)$ 。不过比特币中不需要不存在证明。
比特币中的协议
交易(transaction based ledger)
说比特币之前,我们先看一下中心化的数字货币是怎么进行交易的。
比如央行发行数字货币,央行用私钥对数字货币进行签名,人民群众用央行的公钥进行验证,从而对数字货币的真伪进行判断。
如果说某人有100的数字货币,他可以对这100的数字货币进行复制,这样相当于可以支付两次,也就造成了双花攻击(double spending attack)。
要想预防这种攻击,就需要央行给每个数字货币一个编号,再维护一个数据库。数据库中存有货币的编号及其所属人。当一个人想要进行交易时,需要从数据库中确认货币是否真实以及是否所属于他,都满足后数据库中货币的编号将指向收款人。
但是这样,每次交易太过于依赖一个中心化的机构,这时去中心化的比特币出现了。
比特币,同样也需要解决以下两个问题:
- 谁有权利发行货币,发行多少,什么时候发行?
- 交易如何验证身份?如何防范双花攻击?
第一个问题的答案是挖矿,这个部分后面会进行学习。第二个问题,我们通过以下的具体例子进行解决:

图中,A具有铸币权,发布了10个比特币,第一个区块内的交易也称为铸币交易。同时A转账给B 5个比特币 C 5个比特币,A对该交易进行签名,同时该交易需要说明花掉这10个比特币的来源 —> 铸币中产生的10个币,之后以此类推。
可以看到图中有两类哈希指针(不算块内的交易箭头),一类是指向前一个区块用于形成链,第二类是说明交易比特币的来源(红色➡️),可以防止双花攻击。
通过上述实例,我们可以总结比特币采用的是『 交易追溯 』的方法检验是否满足交易条件。
我们管『 记录账户模式 』的方法叫做 account-based ledger,现实世界以及以太坊,使用的就是这种模式;『 追溯交易模式 』的方法称为 transaction-based ledger。
那么交易的过程,到底需要哪些信息呢?
-
从A —> B 的转账中,A 需要知道 B 的信息:
A 毫无疑问只需要知道 B 的地址就可以了,这个地址由 B 公开的公钥进行二次哈希得到。
-
从A —> B 的转账中,B 需要知道 A 的信息:
B 需要知道 A的公钥,不仅是B所有节点都需要知道A的公钥用于验证A的签名。
这个公钥怎么得到呢?在A交易时,他需要提供出来,同时还需要提供货币来源,这样会不会有安全问题呢?
如果有一个B’冒充A,用自己的私钥进行签名,同时在交易时制定自己的公钥和A的货币来源,那么这样在签名验证肯定是没有问题的,但这无法伪造A的交易。因为追溯货币来源时,会得到A的地址(A的公钥哈希),只需把B所提供的公钥进行哈希之后比对,即可确认是不是存在身份伪造。
在上面的演示中每个区块都只有一个交易,但是实际上一个区块存在多个交易,这些交易也就组织成了 Merkel tree。
挖矿求解
我们一直说挖矿,那挖矿到底是什么?挖矿简单来说就是根据算力,不断去尝试求解一个问题,我们先看看一个 block Header 的组成:
-
version
-
Hash of previous block header (指向前一个区块指针)
-
merkle root hash(默克尔树根哈希值)
-
更新时间
-
target(挖矿难度)
-
nonce (一个随机数)
以上的内容,1-5是固定的,唯一变化的是6,把以上内容首位连接起来,得到一个字符串,对该字符串做两次SHA-256运算,得到256位的B,挖矿,就是不断的随机尝试nonce,直到B ≤ target,通俗一点就是B的前n位为0。
挖矿的具体细节和难度调整会在后面学习到。
分布式共识
分布式共识是什么?如果说系统中有很多台机器,共同维护一个全局的哈希表,那么这里的共识指的就是哈希表中包含了哪些键值对,假如机器 A中插入了一个键值对,那么要求其他机器也能够读出来。
分布式系统有很多结论,这里不展开介绍;
FLP ( 三个专家名字的缩写 )不可能结论:在一个异步的 ( asynchronous ) 系统里,网络时延无上限,即使只有一个成员是有问题的 ( faulty ) ,也不可能达成共识。
CAP Theorem :任何一个分布式系统,Consistency ( 系统一致性 )、Availability ( 可用性 )、Partition tolerance ( 容错性 ) 只能最多满足其中两个性质 。
那区块链中,需要满足怎样的共识呢?答案就是区块的共识,每个全节点都在本地维护了一个区块,这个区块包含了多个交易,那么哪些交易被写进区块,按什么顺序写入,这需要达到一个统一。这么多全节点,那么由哪一个被写入真正的区块链,作为大家所公认的,拥有记账权,这就是共识的问题。
在很多分布式系统中,都采用投票的机制以达到某个共识,但这才区块链中是否可行呢?
如果说这个链对加入的成员有所要求,比如联盟链,那么基于投票是可行的。问题在于区块链创建账号的成本几乎没有,只需要本地产生公私钥对即可,任何人都可以加入,如果黑客专门产生大量的公私钥对,当其超过系统的一半时,就可以获得支配地位,也就是女巫攻击(sybil attack )。
那么区块链是怎么做到呢?区块链采用的是 POW (proof of works )机制,具体运作如下:
step1:全网广播新的数据记录 ,通过基本合法性验证的数据被暂存。这点是说,所有候选区块都是合法区块,非法区块(非法意思是区块中包含的交易不合法)是不会作为候选区块的。
step2:全网执行共识算法,即找到合适的nonce,使得H(Block header)≤target,俗称挖矿
step3:率先找到nonce节点获得记账权,其打包的区块可上传至区块链中
step4:对外广播新区块,其他节点验证通过后,将其加至主链中。
首先确定一点,为什么大家都想打包区块,争夺所谓的记账权呢?挖矿,自然是为了挖矿的奖励:
一个获得合法区块的节点,可以在区块中获得一个铸币交易 ,也就是出块奖励,实际上这种方式也是唯一一个产生新比特币的途径。
比特币系统规定,起初每个打包成功的区块可以获得50个比特币,之后每过 21万个区块,奖励减半,通过计算我们知道比特币一共有2100万个。
原来区块链是通过算力来进行投票,大家争夺的并不是记账权,而是挖矿后的奖励,记账只是在区块链中默认履行的义务。
下面我们再看看在共识中可能出现的几种特殊情况。

上图中,A在第5个区块发布之后,发布了第4’区块,并尝试上传到区块链中,这种情况是否可行?
首先,区块链遵循最长链原则,1-4’ 这条链虽然合法,但不是最长的,对于现在正准备挖矿打包的其他节点而言,他们的父哈希(Hash of previous block header )已经指向了第五个区块,也就决定了之后的候选区块必然是连在5号区块之后的。
那么这种攻击 ( 分叉攻击 ) 有可能成立吗?如果A在上传4’后,马上又计算好了5’区块,然后计算好了6’区块,之后A同时上传,如果整个区块链网络还没能算好第六个区块,他们就会放弃计算6号区块,转而去计算7’,这就是分叉攻击,4号和5号的所有合法交易都被回滚。

理论上是可行的,实际上A所对抗的算力是整个区块链网络的其他所有计算机,所以只有A达到整个系统的 51% 算力,才可能实现。
还有一种情况是自然分叉:

两个符合要求的矿工,同时计算到了nonce并广播,在区块链网络中,有一部分人会接受上面的区块,一部分会接受下面的,分别用上面区块的哈希值作为父哈希进行计算,随着时间推移,总有一条链胜出(他的子节点先挖到矿并打包),成为最长合法链,由此保证了区块链的一致性,而被抛弃的区块称为 orphan block (孤儿区块,没有大爹算出来,是这样的),其中的交易就被全部回滚了。
比特币系统的实现
上一节我们说到比特币采用交易模式是transaction-based ledger,因为系统中并没有显示记录每个账户的比特币数目,需要通过交易回溯推算。因此,在比特币系统中维护了一个 UTXO(Unspent Transaction Output):尚未被花掉的交易。
后面的内容比较简单,介绍了一些具体的区块信息和交易信息,安全性分析也都是共识中谈过的内容,就不记录了。
比特币网络
在网络中需要传播两种信息:新发布交易的信息和新发布区块的信息。
比特币工作于应用层,其网络层为一个P2P overlay network。比特币系统中所有节点完全平等,要想加入网络,至少需要知道一个种子节点,通过种子节点告知他所知道的其他节点。当节点离开时,只需自行退出,其他节点一定时间没有收到该节点信息便会自行删除。
比特币网络设计原则:simple、robust、but not efficient。每个节点维护一个邻节点集合,消息传播在网络中采用flood 模式,某个节点在收到一条消息会将其发送给所有邻居节点并标记,下次再收到便不会再发送该消息,以免消息无限循环。邻居节点选取随机,未考虑网络底层拓扑结构,也与现实世界物理地址无关。该网络具有极强鲁棒性,但牺牲了网络效率。
如果有两个冲突交易 A->B 和 A->C(花费同一笔钱),取决于节点先收到哪个交易,宁外一个将抛弃。
比特币的挖矿难度调整和历史
在比特币系统中,平均出块时间保持到10min 左右,随着挖矿的人增多以及设备的强大,系统总算力不断增强,要想保持出块时间就得对挖矿的难度做出调整。
挖矿难度调整
之前说到挖矿就是不断尝试 block header 中的 nonce 值,使得整个 block header 对两次哈希值小于 target ,那么调整挖矿难度,其实就是调整 target 。
对于挖矿难度,有以下几个问题:
-
如果不调整挖矿难度会怎么样?
随着系统算力的增强,挖矿难度不变,出块时间会越来越短。
-
出块时间越来越短是好事吗?
出块时间短的好处是交易很快能被写入区块链,提高了区块链的效率。但是问题是区块链网络传播有时延,如果出块时间短会使得系统中的节点经常处于不一致的状态,增加了系统的不稳定性,这种不稳定性会导致区块分叉状态过多,不利于达到共识,造成算力分散,黑客如果集中攻击的成本会大大降低。
挖矿历史
列一下全节点和轻节点的区别:
| 全节点 | 轻节点 |
|---|---|
| 一直在线 | 不是一直在线 |
| 在本地硬盘上维护完整区块链信息 | 不保存整个区块链,只需要保存每隔区块块头 |
| 在内存中维护UTXO集合,以便于快速检验交易合法性 | 不保存全部交易,只保存和自己有关的交易 |
| 监听比特币网络中交易内容,验证每个交易合法性 | 无法验证大多数交易合法性,只能检验和自己相关的交易合法性 |
| 决定哪些交易会打包到区块中 | 无法检测网上发布的区块正确性 |
| 监听其他矿工挖出的区块,验证其合法性 | 可以验证挖矿难度 |
| 挖矿: 1 . 决定沿着哪条链挖下去。 2. 当出现等长分叉,选择哪一个分叉 |
只能检测哪个是最长链,不知道哪个是最长合法链 |
目前挖矿越来越趋近于专业化,总体分为三个阶段,从通用演变为专用:
-
CPU阶段
早期,很多人使用自己的个人电脑挖矿,但挖矿过程中大多数的内存,硬盘以及CPU的大部分组件(因为挖矿求解本身运用到的指令就很少)都是闲置状态,随着挖矿难度的提高,用CPU挖矿根本不划算。
-
GPU阶段
GPU主要用作大规模并行计算,如深度学习,但GPU挖矿还是有一定的浪费,比如挖矿只使用整数,浮点数运算的部件将会闲置。
-
ASIC芯片(Application Specific Integrated Circuit)阶段
这种芯片相当于针对一类挖矿的求解问题(mining puzzle)进行针对性设计。
ASIC芯片的出现是好事吗?
ASIC芯片不是每个人都能参与进来,一定程度上提高了挖矿的门槛,这与去中心化相违背。并且ASIC的定制开发需要很长的周期(大于一年),如果这个时间内对应币的价值大幅度贬值价格跳水,投入的成本将血本无归。
理想状态下,所有人应该都可以用家用计算机 CPU 进行挖矿,后续一些货币就考虑了这个问题,设计了对抗 ASIC 芯片化的解决方案,后续的以太坊就会介绍到。
对于单个的矿工而言,即使使用了ASIC芯片,其算力在整个系统中仍然是很小的一部分,并且他还需要担任全节点的其他责任,造成了算力的浪费。
因此,后面变形成了矿池的概念:

一个简单的矿池如上:一个全节点驱动多台矿机。矿工只需要不断的计算哈希即可,其他全节点的责任由矿主承担,当获得收益后,对所有矿工进行分配。
矿池一般有两种组织形式,一是同一机构对大规模数据中心统一挖矿,二是分布式,矿主和矿工不认识,矿工自愿加入矿池,矿主分配任务,但这一种情况的话利益的分配就成了一个问题:
-
平均分配,所有人平分出块奖励
这样肯定不行,首先不同矿工的算力有所差距,而且这种 『 吃大锅饭 』的方式肯定会让有一些矿工偷懒,所以需要按劳分配,要有一个工作量证明的制度。
-
按劳计算,根据工作量分配
假设原本的挖矿难度是计算所得前70位为0,现在降低要求只需前60位,这样挖矿更加容易,当然这个哈希本身是没有用的,并不满足挖矿的条件,我们把其称为一个 share ,或者 almost valid share,矿工没挖到一个share,便提交给矿主,作为其工作量的证明,等某个矿工真正挖到符合条件的区块后,再根据矿工所提交的的share所分配。
注意,每个矿工挖矿都是 随机的 生成nonce并尝试,不会说我从1-10000这个区间尝试,你从10001到20000这样,所有人都是随机的,尽管可能会重合(概率也很低)。
同时,一下几种情况也需要考虑:
-
会不会存在有矿工平时正常挖矿交share,但是挖到真正的矿不是交给矿主而是自己偷偷发布出去(私吞)
这种情况不可能,矿主组装区块交给矿工计算,其中铸币交易的收款地址是矿主,如果矿工修改改地址,其nonce也会失去其意义。
-
会不会有矿工捣乱,平时提交share,挖到区块反而扔掉不提交。
这种情况是有可能的,如果矿工本身想捣乱,可以这么做,虽然对他自身来说没有任何获利,损人不利己。
但是矿池直接是存在竞争关系的,为了打击竞争对手可能排矿机加入对方矿池挖矿,只参与其他矿工挖矿分红,自己挖到的区块却丢掉不给他人分。
随着矿池的出现,算力也变得集中起来,在2014年曾有一个名叫 『 GHash 』的矿池达到了高达 51%的算力:

我们之前说到如果算力达到51%就有可能可以发起分叉攻击,如果攻击者不喜欢某个账户A,在监听到A将交易发布到区块链后,立马发动分叉攻击使A无法成为最长合法链,这样便实现对对A的封锁(Boycott)。
可见矿池的出现威胁了区块链去中心化的特性,之后 GHash 主动降低了矿池算力,避免动摇人们对比特币的信心。
如果矿池表面上是安全的,实际上某个机构拥有超过百分之50的算力,不将其放入一个矿池中而是分散隐蔽,还是可以发动51%算力的攻击。
比特币分叉
分叉是指原来比特币系统中的一条链变成了两条链。造成分叉的原因有很多,简单来说有以下三种:
- state fork:两个时间差不多的矿工同时出矿,发布区块对比特币系统当前状态产生分歧的分叉。
- forking attack:人为分叉攻击造成的分叉。
- protocal fork:比特币协议改变,在分布式系统中不是所有的节点都进行升级,导致分叉。
而这一节所说的分叉,主要就是围绕 protocal fork 所展开的,比特币协议改变,简单来说就是进行了更新。
回想一下我们现实软件中更新的例子,有的软件会在打开时提示你是否进行更新,你可以根据产品变更自行选择;有的软件会在下载时就默认确认自动更新,在连网的情况下自动获取数据包;有的软件在你选择是否更新后(否)自动退出,默认不进行更新则无法继续使用,这都是非常常见的例子。
说到更新其实离不开一个兼容性的问题,我在这个方面被小绕晕了一会,也简单谈谈 兼容性的异议 1:
兼容性主要分为 向前兼容(Forward Compatibility)和 向后兼容 (Backward Compatibility)两种,这里主要的异议在于英文中,前后 两词在时间上和空间上是统一的,比如 Forward 在空间上指前进,时间上指未来,而汉语中 『 前 』 在空间上指前进,时间上通常指以前,过去。
而正是这种差异,我也赞同知乎下面的一个评论,不如把这两者直译为:Forward Compatibility 兼容未来,Backward Compatibility 兼容过去。
兼容未来(Forward Compatibility):指老的软件 / 硬件 兼容新的软件 / 硬件 的数据,如果在现实中会少一些,因为开发者需要在设计之初考虑各种情况,比如 HTML 页面就是兼容未来的,浏览器遇到新版本的 HTML语言时,即使有一些标签无法不支持,也会选择忽视正常使用,而比如 lambda 表达式是 java 8 所推新的特性,如果是java 5的编译器则会报错,这就是不兼容未来的例子。
兼容过去(Backward Compatibility ):指新的软件 / 硬件 兼容老的软件 / 硬件 的数据,这个在大部分的编程语言中都满足,即使有一些特性被删去,也只是给出一个 warning,并不影响正常编译使用。但很多软件就不这样,因为设计之初没有考虑到很多情况,可能必须要抛弃过去的一些特性,只能强行更新不兼容。
好了刚刚我们聊的都是现实生活的例子,通常会有一个管理方或者平台分发更新的报告,而在加密货币体系中,去中心化的环境并没有严格的层次结构,所谓更新只是矿工们广义上达到的某种 共识 而已,比较不可能会有人顺着地址摸到矿工家里拿着枪逼他进行更新。
其实上面的两种兼容模式都是我另外补充的,肖臻老师在课堂上只用两个例子来描述软硬分叉,可能我理解能力比较差所以另外补充了一些知识进行概括,如果有不对的地方还望批评指正。
硬分叉
硬分叉用一句话概括就是 兼容过去,但不兼容未来。比特币协议修改后,未升级的节点不会认可这些修改,会认为这些特性是违法的,从而导致分叉,我们以一个具体的情况为例:
在BTC系统中,区块大小最大为1MB,可以包含的交易最大数量为4000笔左右。而一个区块产生大概需要10min左右,也就是说,整个比特币系统,平均每10分钟最多只能处理4000笔交易(平均每秒7笔交易),严重影响了吞吐率和交易处理,所以有人认为可以增大区块大小,使得一个区块中包含的交易数变多,我们假设区块大小从1MB增大到8MB。
我们假设系统中大多数节点都进行了更新,只有少部分 守旧派 不愿意增大(区块增大也会导致网络传输变慢)。我们这里的大多数和少部分单纯指的是算力,而不是具体的人数。

如上草图所示,图 1 为当前区块链,此时协议更新,绿色的新节点挖到了区块,如图2。但是对于旧节点来说因为不向未来兼容,它认为这是一个非法区块,故旧节点依旧照绿色区块前一个区块挖矿,如图三。
但是因为新节点的算力强,它会沿着上方的最长合法链进行挖矿,而对于旧节点来说,上方链上存在非法区块,不会认可该链,也沿着自己下方的链挖矿,可见这种分叉是持续性的,只要这部分旧节点不更新,下方的链就永远不会消失。
历史上BTC的分叉币BCH(比特币现金,区块大小为)就是这样硬分叉而来。而以太坊网络也同样发生过硬分叉,不过那是因为智能合约 THE DAO 存在重入漏洞,被黑客攻击后不得不以硬分叉的方式回滚交易,具体内容会在后续的以太坊中介绍。
软分叉
关于软分叉的定义,其实我一直没有找到一个比较明确的结论,反而是在不同的资料上有不同的解释:大多数科普文章把软分叉归结于同时 兼容未来和兼容过去,即新旧节点可以完全共存在一条最长链上;而肖臻老师的讲义上举的例子是兼容未来,但不兼容过去。我暂且理解是否兼容过去取决于具体的协议变更,这么看维基百科上关于软分叉的描述可能更加规范2:
与硬分叉相比,软分叉所产生之区块能够被旧软件识别为有效区块,即区块 向下兼容。然而,旧软件所产生之区块则未必在新规则下有效。
我们同样以区块大小为例,不过这次更新是把区块变小,从1MB变为0.5MB。
注意这里只是简单打了一个比方,实际上更新不是简单调整一个参数那么简单,因为是否兼容一定意义上就是取决于修改协议的部分。
我们假设大多数节点进行了更新(即更新之后的节点算力超过 50%),如果软分叉满足兼容过去,那么应该会出现以下这种情况:


如果新节点不认可大于0.5MB的旧节点的话,认为其是一个非法区块,会从其前一个小区块开始,而旧节点一直被抛弃,不在最长合法链上,导致得不到出块奖励,最后逼迫旧节点升级,实现区块链上的所有矿工共同认可新协议,实现软件协议的升级。
比特币中的很多功能都是后续通过软分叉加入其中,比如在比特币系统中简单带过的 UTXO,就是通过软分叉写入到了 CoinBase域,旧节点认可新节点的区块,但是新节点检查旧节点 CoinBase域时发现并没有UTXO,则不会认可其发布的区块。不过更新也是一个慢慢迭代的过程,我们上面所举的例子也是站在已经有 50%的用户进行更新的前提下。
总结:
硬分叉:必须系统中所有节点更新软件,系统才不会产生永久性分叉,当出现更新时,硬分叉导致用户必须做出选择,会把社区一分为二。
软分叉:比较平稳,新的升级不会造成某种冲突,只需要实施某种限制,只要系统中一半以上的算力更新软件,系统就不会产生永久性分叉。
以太坊
以太坊概述
BTC成为区块链1.0,以太坊成为区块链2.0。以太坊的出现,弥补了之前我们所说区块链存在的一些不足,比如:
-
挖矿时间
比特币的出块时间为10min,很多人觉得这个时间太长了,在以太坊中大幅度见减小,改为10多秒。
-
共识机制不同
针对以太坊的出块时间,以太坊研究出了 『 基于 Ghost 协议 』的共识机制。
-
mining puzzle
比特币中的 mining puzzle 是纯暴力计算哈希,这样的结果是挖矿设备专业化。但这一定意义上违背了去中心化原则。以太坊的 mining puzzle 对内存是有一定要求的,这一定意义上限制了 ASIC 芯片的使用。
- 以太坊用权益证明(pos proof of stake)代替了 工作量证明(pow)。
- 以太坊引入了对智能合约(smart contract)的支持。
以太坊账户
BTC系统是基于交易的账本,系统没有记录每个账户有多少钱,只能通过 UTXO 进行推算。
以太坊系统采用了账户的模式,和现实中的银行类似。
以太坊中,有两类账户:外部账户和内部账户。
- 外部账户(externally owned account),存有类似BTC系统中的公私钥对、余额和计数器。
- 合约账户(smart contract account):不能主动发起交易,只能接收到外部账户调用后才能发起交易或调用其他合约账户,其除了balance和nonce之外还有code(代码)、storage(相关状态-存储)。
创建合约时会返回一个地址,通过地址即可调用。
以太坊中的数据结构
状态树
交易树
收据树
工作比较忙,以太坊这部分就不整理了。