大二买了这本书一直没看,最近有Linux这门课还是简单记录了一下(纯纯API翻译小能手)。感觉虽然涉及的知识比较全,但是一些我觉得比较重要的点却是一笔带过了,不过好在在APUE和UNP中都找到了答案。
基础API
socket基础API
//1. 主机序和网络字节序转换
#include <netinet/in.h>
unsigned long int htonl (unsigned long int hostlong); // host to network long
unsigned short int htons (unsigned short int hostlong); // host to network short
unsigned long int ntonhl (unsigned long int netlong);//network to host long
unsigned short int ntohs (unsigned short int netlong);//network to host short
//2. socket地址
//2.1 通用socket结构 sockaddr
struct sockaddr
{
sa_family_t sa_family; /* 地址族,AF_XXX */
char sa_data[14]; /* Address data.包含目的地址和端口信息 */
};
/*
sa_family: 2字节地址族:
AF_UNIX :UNIX本地地址族
AF_INET :TCP/IPv4地址族
AF_INET6:TCP/IPv6地址族
*/
//2.2 专用socket结构 sockaddr_in,与前者相比把port和addr分开存储到了两个变量中
struct sockaddr_in
{
sa_family_t sin_family; /* 地址族,AF_XXX */
in_port_t sin_port; /* 端口号,要用网络字节序*/
struct in_addr sin_addr; /* IPv4地址结构体,见↓ */
};
//存储IPv4的数据结构
struct in_addr
{
uint32_t s_addr; /* IPv4地址,要用网络字节序表示*/
};
//3. IP地址转换函数
#include <arpa/inet.h>
// 将点分十进制字符串的IPv4地址, 转换为网络字节序整数表示的IPv4地址. 失败返回INADDR_NONE
in_addr_t inet_addr( const char* strptr);
/*例如:*/ sockaddr_in.sin_addr.s_addr=inet_addr("127.0.0.1");
// 功能相同不过转换结果存在 inp指向的结构体中. 成功返回1 反之返回0
int inet_aton( const char* cp, struct in_addr* inp);
//将IPv4地址转化为点分十进制IP地址字符串,和上述两个函数功能相反
//该函数使用一个内部静态存储转化结果,函数返回值指向该静态内存,所以此函数是不可重入的!
char* inet_ntoa(struct in_addr in);
//以下函数也能完成前面3个函数同样的功能,并且同时适用于IPv4和IPv6
//将点分十进制或者十六进制IP地址转化为网络字节序表示的地址
int inet_pton(int af, const char * src, void* dst);
/*
af:地址族 AF_INET or AF_INET6
src:IP地址
dst:转化的地址
成功返回1,失败返回0并设置errno
*/
//和上述功能相反
const char* inet_ntop(int af, const void* src, char* dst, socklen_t cnt);
/*
前三者和inet_pton一样,src和dst交换了顺序
cnt指定目标存储单元大小,可用INET_ADDRSTRLEN, INET6_ADDRSTRLEN表示
*/
//4. 创建socket
int socket(int domain, int type, int protocol);
/*
domain:底层协议族
PF_UNIX :UNIX本地协议族
PF_INET :TCP/IPv4协议族
PF_INET6:TCP/IPv6协议族
(地址族和协议族事实上是一一对应的,在前UNIX时代有所区分,在Linux上已完全兼容,不过为了规范区分一下也行)
type:通讯类型(服务类型)
SOCK_STREAM(流服务,TCP协议)
SOCK_DGRAM(数据报服务,UDP类型)
protocol:通常为0
socket调用成功时返回一个socket文件描述符,失败返回-1并设置errno
*/
//5. 命名socket
//作用于服务端,将一个socket和socket地址进行绑定称为给socket命名
int bind(int socket, const struct sockaddr* my_addr, socklen_t addrlen);
/*
socket:创建socket返回的文件描述符
my_addr:my_addr所指的socket地址
addrlen:socket结构长度
成功返回0,失败返回-1
*/
//6. 监听socket
//作用于服务端,监听socket所绑定的套接字
int listen(int socket, int backlog);
/*
socket:创建socket返回的文件描述符
backlog表示队列最大的长度
如果长度超过backlog,客户端会受到ECONNREFUSED错误信息
*/ok'l'l
//7. 接受连接
//作用于服务端,响应连接请求,建立与Client连接
int accept(int sockfd, struct sockaddr* addr, socklen_t* addrlen)
/*
sockdf:创建socket返回的文件描述符
addr:获取被接收的远程socket地址
addrlen:addr长度
成功返回用于和Client数据传输的文件描述符
*/
//8. 发起连接
//作用于Client程序,连接到某个服务端
int connect(int sockfd, const struct sockaddr * serv_addr, socklen_t addrlen);
/*
sockdf:创建socket返回的文件描述符
serv_addr:被连接服务器信息
addrlen:serv_addr长度
成功返回0 失败返回-1
*/
//9. 关闭socket
#include <unistd.h>
int close(int fd);
//并非立即关闭, 将socket的引用计数-1, 当fd的引用计数为0, 才是真正的关闭。(多进程fork调用会是父进程socket引用+1)
// 立即关闭
#include <sys/socket.h>
int shutdown(int sockfd, int howto)
/*
第二个参数为可选值
SHUT_RD 关闭读, socket的接收缓冲区的数据全部丢弃
SHUT_WR 关闭写 socket的发送缓冲区全部在关闭前发送出去
SHUT_RDWR 同时关闭读和写
成功返回0 失败为-1 设置errno
*/
数据读写
//1. TCP数据读写
#include<sys/socket.h>
ssize_t recv(int sockfd, void *buf, size_t len, int flags);
/*
buf:指向接受信息的缓冲区指针
len:buf缓冲区大小
flags:一般设置为0,特殊情况查表
返回成功接受的字节,0表示已关闭,失败返回-1
*/
ssize_t send(int sockfd, const void *buf, size_t len, int flags);
/*
buf:指向需要发送信息的缓冲区指针
len:buf缓冲区大小
flags:一般设置为0,特殊情况查表
返回成功发送的字节数,失败返回-1
*/
//2. UDP数据读写
#include <sys/socket.h>
// 由于UDP不保存状态, 每次发送数据都需要 加入目标地址.
// 如果实现有建立连接,把最后两项设为null,等同于TCP数据读写
ssize_t recvfrom(int sockfd, void *buf, size_t len, int flags, struct sockaddr* src_addr, socklen_t* addrlen);
ssize_t sendto(int sockfd, const void* buf, size_t len, ing flags, const struct sockaddr* dest_addr, socklen_t addrlen);
//3. 通用数据读写
#inclued <sys/socket.h>
ssize_t recvmsg(int sockfd, struct msghdr* msg, int flags);
ssize_t sendmsg(int sockfd, struct msghdr* msg, int flags);
//msg参数是msghdr结构体类型的指针,msghdr结构体类型定义如下:
struct msghdr
{
//指向socket地址结构变量, 对于TCP连接需要设置为NULL
void* msg_name;
socklen_t msg_namelen;
/*
分散的内存块
对于 recvmsg来说数据被读取后将存放在这里的块内存中, 内存的位置和长度由msg_iov指向的数组指定, 称为分散读(scatter read)
对于sendmsg而言, msg_iovlen块的分散内存中的数据将一并发送称为集中写(gather write);
*/
struct iovec* msg_iov;
int msg_iovlen; /* 分散内存块的数量*/
void* msg_control; /* 指向辅助数据的起始位置*/
socklen_t msg_controllen; /* 辅助数据的大小*/
int msg_flags; /* 复制函数的flags参数, 并在调用过程中更新*/
};
struct iovec
{
void* iov_base /* 内存起始地址*/
size_t iov_len /* 这块内存长度*/
}
其他API
网络信息API
//1. 获取主机信息
#include <netdb.h>
//1.1 通过主机名获取主机信息
struct hostent* gethostbyname(const char* name);
//1.2 通过ip获取主机完整信息
struct hostent* gethostbyaddr(const void* addr, size_t len, int type);
// type为IP地址类型 AF_INET和AF_INET6
struct hostent
{
char *h_name; //主机名
char **h_aliases; //主机别名 可能有多个
int h_addrtype; //地址组
int h_length; //地址长度
char **h_addr_list; //按网络字节序列出的主机IP地址列表
}
//2. 获取服务信息
#include <netdb.h>
//2.1 根据名称获取某个服务的完整信息
struct servent getservbyname(const char* name, const char* proto);
//2.2 根据端口号获取服务信息
struct servent getservbyport(int port, const char* proto);
struct servent
{
char* s_name; /* 服务名称*/
char ** s_aliases; /* 服务的别名列表*/
int s_port; /* 端口号*/
char* s_proto; /* 服务类型, 通常为TCP或UDP*/
}
高级I/O函数
不像基础I/O函数那么常用,但在特定的条件下却表现出优秀的性能。
//创建管道,实现进程间通讯
#include <unistd.h>
//从fd[1]写入的数据可以从fd[0]读出
int pipe(int fd[2]);
//双向管道
#include <sys/socket.h>
int socketpair(int domain, int type, int protocol, int fd[2]);
//输入重定向
//复制一个现有的文件描述符,返回的文件描述符总是取系统当前可用的最小整数值
#include <unistd.h>
int dup(int oldfd);
//分散读和集中写
ssize_t readv(int fd, const struct iovec* vector, int count);
ssize_t writev(int fd, const struct iovec* vector, int count);
struct iovec {
void* iov_base /* 内存起始地址*/
size_t iov_len /* 这块内存长度*/
}
//传输文件
#include <sys/sendfile.h>
// offset为指定输入流从哪里开始读, 如果为NULL 则从开头读取
ssize_t sendfile(int out_fd, int in_fd, off_t* offset, size_t count);
//可以使用writev发送文件,但是sendfile没有分配用户空间的缓存,也没有执行读取文件的操作,效率会高一些。
//两个文件描述符之间移动数据,零拷贝
#include <fcntl.h>
ssize_t splice(int fd_in, loff_t* off_in, int fd_out, loff_t* off_out, size_t len, unsigned int flags);
//举个例子 echo服务器
int connfd = accept......;
int pipefd[2];
//把connfd上流入的客户端数据定向到管道
splice( connfd, NULL, pipefd[1], NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE );
//把管道的输出数据定向到connfd客户连接文件描述符
splice( pipefd[0], NULL, connfd, NULL, 32768, SPLICE_F_MORE | SPLICE_F_MOVE );
//tee也可以用作数据复制,不过只能用于管道文件描述符
ssize_t tee(int fd_in, loff_t* off_in, int fd_out, loff_t* off_out, size_t len, unsigned int flags);
I/O复用
I/O复用使得程序能同时监听多个文件描述符,通常网络程序在下列情况需要使用I/O复用技术。
- 客户端程序需要同时处理多个socket 非阻塞connect技术
- 客户端程序同时处理用户输入和网络连接 聊天室程序
- TCP服务器要同时处理监听socket和连接socket
- 同时处理TCP和UDP请求 - 回射服务器
- 同时监听多个端口, 或者处理多种服务 - xinetd服务器
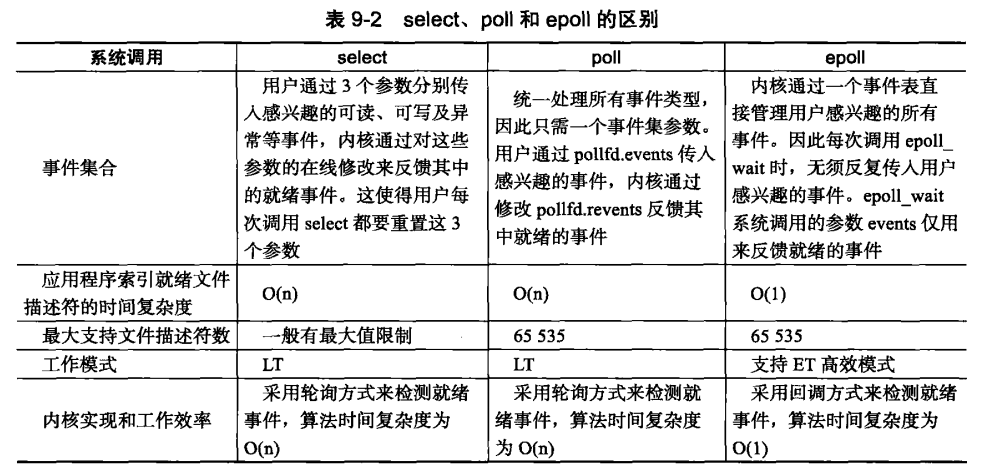
Linux下实现I/O复用的系统屌用主要有select, poll, epoll。
其实在使用golang的过程中,很多函数都封装了I/O复用,只是我们没有深入到里面去理解。
select
select系统调用可监听算选的文件描述符,并根据文件描述符返回的 可读、可写、异常 等事件做出不同的回应。
一个例子,socket接受普通数据和外带数据都处于就绪态,但是前者是可读模式,后者是异常模式:
...
int connfd = accept(...);
fd_set read_fds;
fd_set exception_fds;
FD_ZERO( &read_fds );
FD_ZERO( &exception_fds );
while( 1 )
{
memset( buf, '\0', sizeof( buf ) );
//每次select前为什么都要重新设置文件描述符
FD_SET( connfd, &read_fds );
FD_SET( connfd, &exception_fds );
ret = select( connfd + 1, &read_fds, NULL, &exception_fds, NULL );
printf( "select one\n" );
if ( ret < 0 )
{
printf( "selection failure\n" );
break;
}
//可读模式
if ( FD_ISSET( connfd, &read_fds ) )
{
ret = recv( connfd, buf, sizeof( buf )-1, 0 );
if( ret <= 0 )
{
break;
}
printf( "get %d bytes of normal data: %s\n", ret, buf );
}
//异常模式
else if( FD_ISSET( connfd, &exception_fds ) )
{
//使用外带数据的读取函数
ret = recv( connfd, buf, sizeof( buf )-1, MSG_OOB );
if( ret <= 0 )
{
break;
}
printf( "get %d bytes of oob data: %s\n", ret, buf );
}
}
针对上述例子分析:
//select调用原型
#include <sys/select.h>
int select (int nfds, fd_set* readfds, fd_set* writefds, fd_set* exceptfds, struct timeval* timeout);
/*
nfds:被监听的文件描述符总数,通常是select监听的文件描述符最大值+1
后三者分别对应可读、可写、异常文件描述符合集,内核通过修改它们来通知哪些文件描述符已就绪。
timeval:select超时时间 如果传递0 则为非阻塞, 设置为NULL则为阻塞
*/
//fd_set结构体仅仅包含一个整形数组,该数组每个元素的每一位标记一个文件描述符
#include <sys/select.h>
FD_ZERO(fd_set *fdset); //清除fdset的所有位
FD_SET(int fd,fd_set *fdset); //设置fdset的fd位
FD_CLR(int fd,fd_set *fdset); //清除fdset的fd位
int FD_ISSET(int fd,fd_set *fdset));、//检查fdset的fd位是否被设置
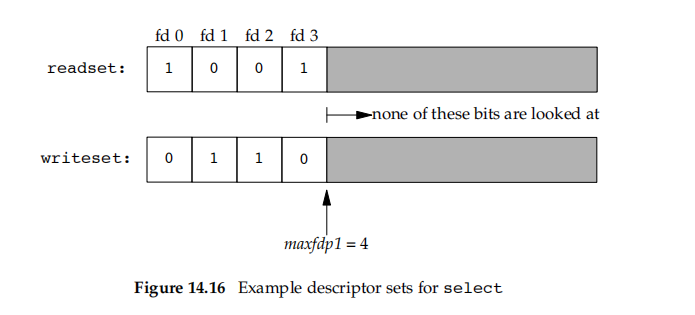
FD_ZERO(&readset);
FD_ZERO(&writeset);
FD_SET(0, &readset);
FD_SET(3, &readset);
FD_SET(1, &writeset);
FD_SET(2, &writeset);
select(4, &readset, &writeset, NULL, NULL);
对应fd_set图:
上面的例子刚开始我有两个疑问:
- 为什么select前都要重新设置文件描述符
- 为什么select前设置了FD_SET,之后又用FD_ISSET判断
原因其实就是事件发生后,会重新设置fd_set,没有事件发生的fd位会被清空。
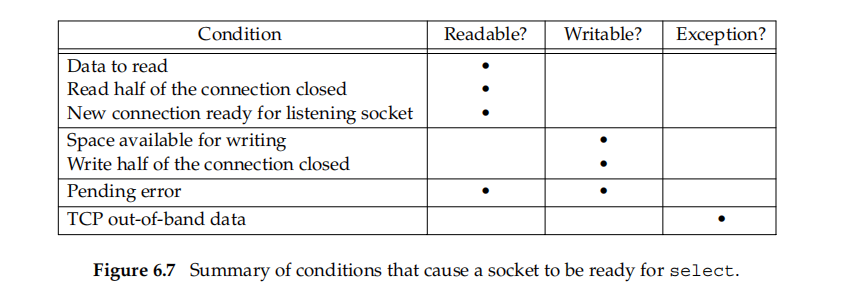
有哪一些事件可以归于可读、可写、异常:
poll
#include <poll.h>
int poll(struct pollfd* fds, nfds_t nfds, int timeout);
/*
fds: pollfd 结构体类型数组,指定文件描述符上发生的可读可写和异常事件
nfds:被监听集合fds大小
timeout 单位为毫秒 -1 为阻塞, 0 为立即返回
*/
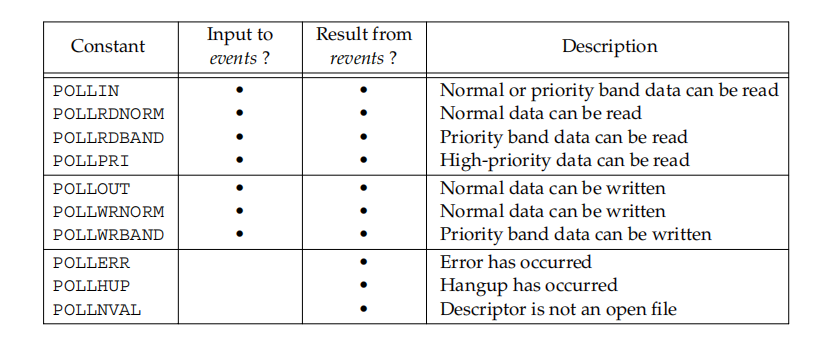
struct pollfd
{
int fd;
short events; //注册的事件, 告知poll监听fd上的哪些事件
short revents; // 实际发生的事件
}
poll支持的事件类型:
结合书上例子用poll写了一个聊天室,感觉用起来的确比select方便一些
epoll
epoll底层使用了红黑树,性能方面最好,相对而言也是用的最多的
//1. 创建epoll实例,在内核中注册一个数据
//失败返回-1,成功返回epoll实例描述符
int epoll_create(int size); //自从Linux 2.6.8 size参数没有意义,但不能设置为0
//2. 操作epoll实例,对内核时间表进行增添、删除、修改操作
int epoll_ctl(int epfd,int op,int fd,struct epoll_event *event);
/*
epfd:epoll实例描述符
fd: 要检测的文件描述符
op:需要进行的操作:
EPOLL_CTL_ADD:添加
EPOLL_CTL_DEL:删除
EPOLL_CTL_MOD:修改
event:检测文件描述符的具体事件
*/
struct epoll_events
{
_uint32_t events; //epoll事件类型,和poll基本上类似,需要在poll的对应宏基础上加上‘E’,两个额外的事件类型EPOLLET和EPOLLONESHOT
epoll_data_t data;//union类型,其中的fd需要设置
}
//3. 检测epoll实例
//成功已就绪的文件描述符个数,失败返回-1
int epoll_wait(int epfd, struct epoll_event *events,int maxevents, int timeout);
/*
epfd:epoll实例的文件描述符
events:传出参数,根据epfd从内核事件表中把所有已就绪的事件复制到events结构体数组中
maxevents:events结构体数组大小
timeout:-1堵塞,大于等于0表示堵塞时间
*/
epoll和poll最大 差异在于:
// 索引poll返回的就绪文件描述符
int ret = poll(fds, MAX_EVENT_NUMBER - 1);
// 遍历
for(int i = 0; i < MAX_EVENT_NUMBER; ++i) {
if(fds[i].revents & POLLIN) {
int sockfd = fds[i].fd;
}
}
// 索引epoll返回的就绪文件描述符
int ret = epoll_wait(epoll_fd, events, MAX_EVENT_NUMBER, -1);
for(int i = 0; i < ret; i++) {
int sockfd = events[i].data.fd;
}
epoll分LT(Level Trigger)和ET(Edge Trigger)两种模式,LT是默认模式,通知一个事件,程序可能不会马上处理完毕,那么下次还会通告此事件;ET是高效模式,只通知一次,所以必须做完。
对比LT和ET,对于BUFFER_SIZE只有10的情况:
LT:
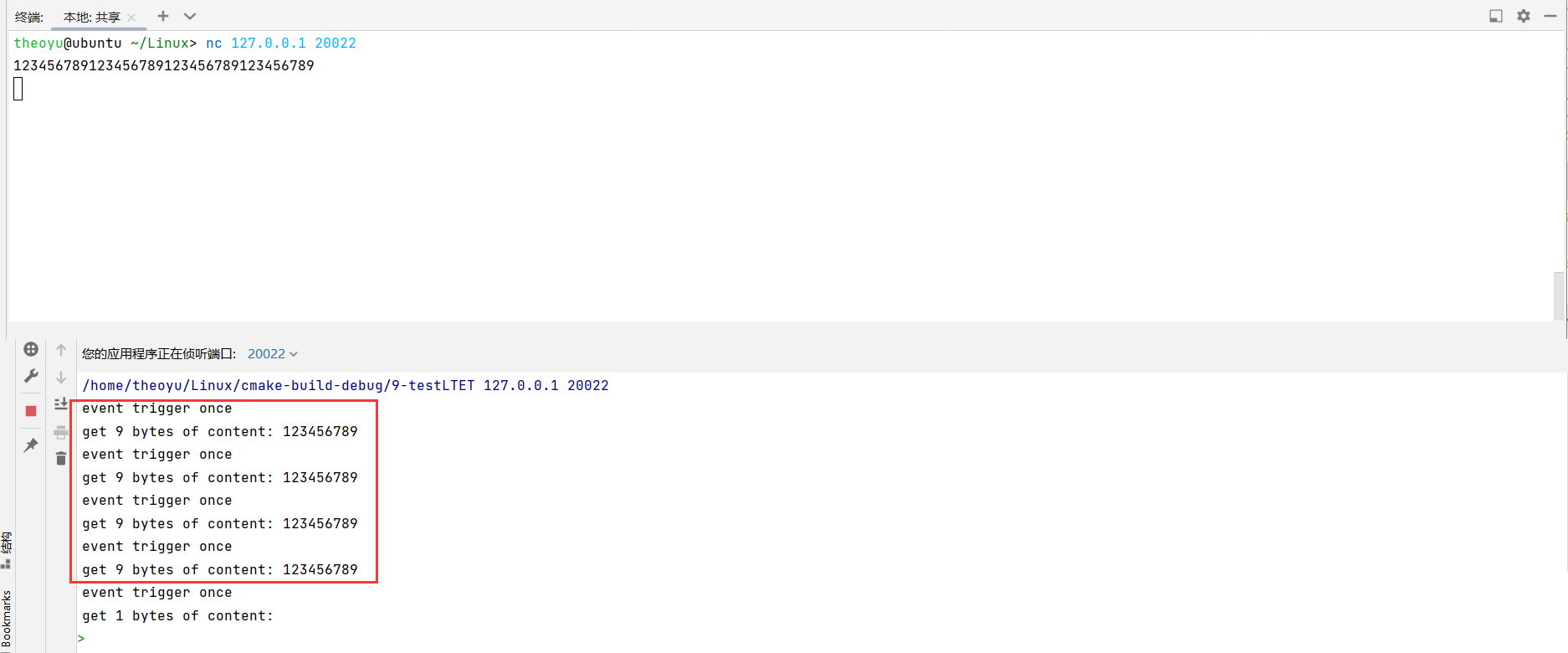
除去换行符出发了4次事件
ET:
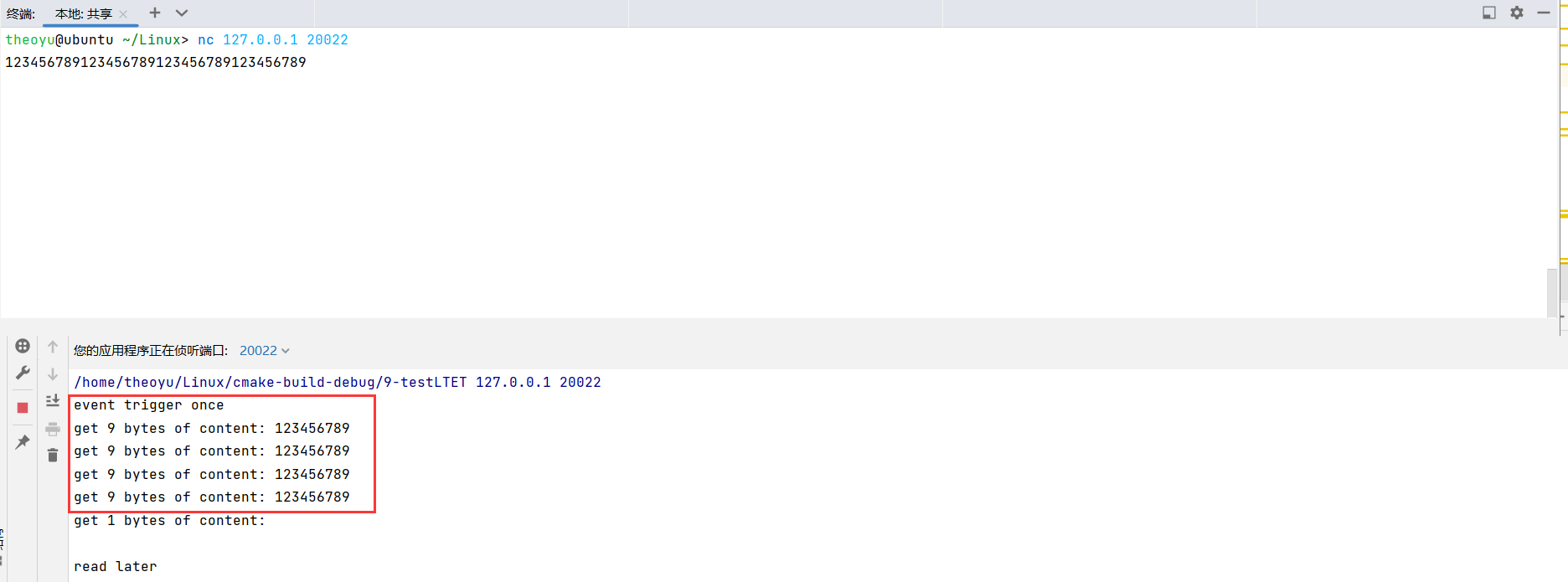
只触发了一次
三组I/O复用的比较
信号
信号是由用户、系统或者进程发送给用户进程的信息,以通知目标进程某个状态的改变或者系统异常
Linu信号可由如下信号条件产生:
- 前台进程
Ctrl+C发送中断进程 - 系统异常。比如浮点异常或者非法内存段异常。
- 系统状态变化。比如alarm定时器引起SIGALRM信号。
- 运行kill命令或调用kill函数
发送信号:
#include <signal.h>
int kill(pid_t pid, int sig);
/*
pid > 0 发送给PID为pid标识的进程
0 发送给本进程组的其他进程
-1 发送给进程以外的所有进程, 但发送者需要有对目标进程发送信号的权限
< -1 发送给组ID为 -pid 的进程组中的所有成员
出错信息 EINVAL 无效信号, EPERM 该进程没有权限给任何一个目标进程 ESRCH 目标进程(组) 不存在
sig具体在bits/signum.h中
*/
alarm定时器:使用alarm函数可设置可以定时器,在未来某个时间定时器会超时,产生SIGALRM信号,如果忽略或者不捕捉信号,默认动作是终止调用该alarm函数的进程。
#include <unistd.h>
unsigned int alarm(unsigned int seconds);
信号处理方式:
// 忽略目标信号
#define SIG_DFL ((_sighandler_t) 0)
// 使用信号的默认处理方式
#define SIG_IGN ((_sighandler_t) 1)
//为单独的信号设置处理函数
#include <signal.h>
// _handler 指定sig的处理函数
_sighandler_t signal(int sig, __sighandler_t _handler)
int sigaction(int sig, struct sigaction* act, struct sigaction* oact);
//一个例子
void addsig( int sig )
{
struct sigaction sa;
memset( &sa, '\0', sizeof( sa ) );
sa.sa_handler = sig_handler;
sa.sa_flags |= SA_RESTART;
sigfillset( &sa.sa_mask );
assert( sigaction( sig, &sa, NULL ) != -1 );
}
## 定时器
基于升序链表的计时器
详情见书籍源码,升序链表可按照活动时间排序,核心是一个心搏函数,每隔一段时间检测到期的任务。
时间轮 And 时间堆
🐦🐦🐦
多进程编程
基础api..:
fork;
exec;
exit;
wait;
waitpid;
chdir;//修改当前工作目录
进程间通信(Inter-Process Communication,IPC)
管道 Pipe
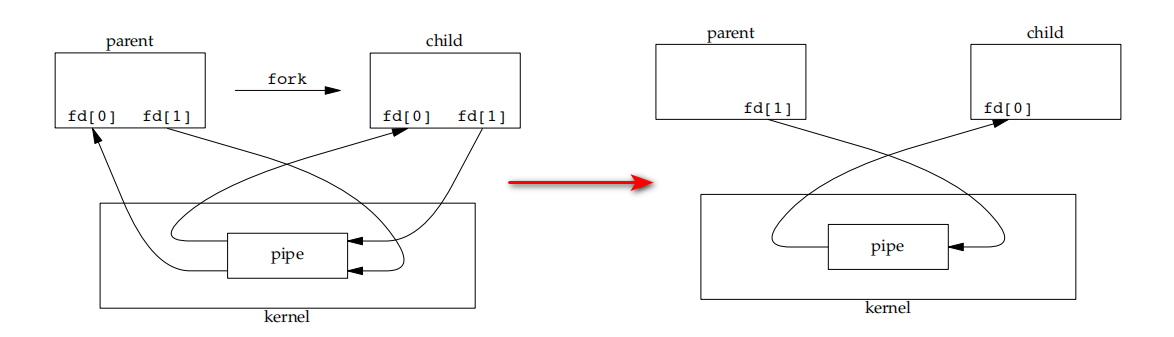
管道本身是单向的,可以用两个管道实现双向传输,也可以使用socketpair来创建双向管道。
信号量 semophore
主要用作进程同步,以确保某一时刻只有一个进程可以拥有资源的独占式访问。
//1. 创建信号量
//创建一个全局唯一的信号量集, 或者获取一个已经存在的信号量集
int semget(key_t key, int num_sems, int sem_flags);
/*
key:所创建信号集的键值,需要时唯一的非整数
num_sens:创建的信号集中的信号量个数,一般为1,若是获取一个已经存在的集合,则为0
sem_flags:0666|IPC_CREAT、 IPC_EXCL
*/
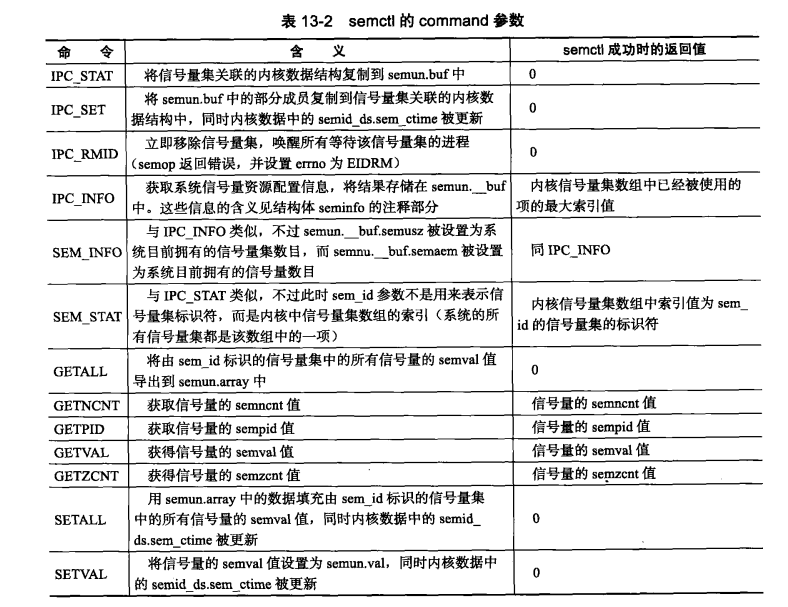
//2. 信号量初始化
int semctl(int sem_id, int sem_num, int command, ...);
/*
sem_id:semget所返回的信号量标识符
sem_num:被操作信号量在信号集中的编号
command:如下图
...:command所需的参数,联合数据类型
*/
union semun
{
int val; /* Value for SETVAL */
struct semid_ds *buf; /* Buffer for IPC_STAT, IPC_SET */
unsigned short *array; /* Array for GETALL, SETALL */
struct seminfo *__buf; /* Buffer for IPC_INFO
(Linux-specific) */
};
//3. 操作信号量(PV)
void pv(int sem_id,int op){
struct sembuf sem_b;
sem_b.sem_num=0;//信号量编号
sem_b.sem_op=op; //-1为P操作,1为V操作
sem_b.sem_flg=SEM_UNDO;
// IPC_NOWAIT 无论信号量操作是否成功, 都立即返回
// SEM_UNDO当进程退出的时候, 取消正在进行的semop操作 PV操作系统更新进程的semadj变量
semop(sem_id,&sem_b,1) m
}
消息队列 message queue
主要用作进程间传递消息。
//1. 创建消息队列
int msgget(key_t key, int msgflg);//和semget类似,成功返回标识符
//2. 发送消息
//成功返回0,失败返回-1
int msgsnd(int msqid, const void *msg_ptr, size_t msg_sz, int msgflg);
/*
msqid:消息队列标识符
msg_ptr:将发往消息队列的消息结构体指针,结构为:
struct msg_st{
long msg_type; //消息类型,用户自定义,接收方会根据类型选择接受
char text[BUFSIZ]; //发送的消息,不一定是char
};
msg_sz:消息结构体中待传输数据的大小
msgflag:IPC_NOTWAIT(消息队列满时返回-1)、0(消息队列满时堵塞)
*/
//3. 接受消息
int msgrcv(int msqid, void *msg_ptr, size_t msg_sz, long int msgtype, int msgflg);
/*
除了msgtype,其他四个参数同msgsnd
msgtype:
msgtype = 0 读取消息队列第一个消息
msgtype > 0 读取消息队列第一个类型是msgtype的消息 除非标志了MSG_EXCEPT
msgtype < 0 读取第一个 类型值 < abs(msgtype)的消息
*/
//4. 控制消息队列
int msgctl(int msqid, int command, struct msqid_ds *buf);
/*
msqid:消息队列标识符
command:
PC_STAT 复制消息队列关联的数据结构存储在buf中
IPC_SET 将buf中的部分成员更新到目标的内核数据
IPC_RMID 立即移除消息队列, 唤醒所有等待读消息和写消息的进程
msqid_ds:如下图
*/

共享内存 shared memory
🐦🐦🐦
多线程编程
线程API
//1. 创建线程
成功返回0,失败返回错误码
int pthread_create(pthread_t* thread, const pthread_attr_t* attr, void* (*start_routine)(void*), void* arg);
//2. 退出线程
void pthread_exit(void* retval);
//3. 回收(等待)线程,类似进程中的waitpid
//成功时返回0, 失败返回错误码
int pthread_join(pthread_t thread, void** retval);
//4. 终止线程
//成功时返回0, 失败返回错误码
int pthread_cancel(pthread_t thread)
多线程同步
互斥量
互斥量主要用于同步线程对共享数据的访问。
// 初始化互斥锁
// 第一个参数指向目标互斥锁, 第二个参数指定属性 nullptr则为默认
int pthread_mutex_init(pthread_mutex_t *mutex, const pthread_mutexattr_t *mutexattr);
// 销毁目标互斥锁
int pthread_mutex_destory(pthread_mutex_t *mutex);
// 针对普通锁加锁
int pthread_mutex_lock(pthread_mutex_t *mutex);
// 针对普通锁立即返回 目标未加锁则加锁 如果已经加锁则返回错误码EBUSY
int pthread_mutex_trylock(pthread_mutex_t *mutex);
// 解锁 如果有其他线程在等待这个互斥锁, 则其中之一获得
int pthread_mutex_unlock(pthread_mutex_t *mutex);
条件变量
条件变量主要用于线程之间同步共享数据的值,条件变量提供了一种线程间的通知机制,当某个共享数据达到某个值时,唤醒等待这个共享数据的线程。
//初始化条件变量
int pthread_cond_init(pthread_cond_t *cond, const pthread_condattr *cond_attr);
//下述相当于初始化一个字段全为空的条件变量
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
// 销毁一个正在被等待的条件变量 将会失败并返回EBUSY
int pthread_cont_destory(pthread_cond_t *cond);
// 广播式的唤醒所有等待目标条件变量的线程
int pthread_cont_broadcast(pthread_cond_t *cond);
// 唤醒一个等待目标条件变量的线程
int pthread_cond_signal(pthread_cond_t *cond);
// 等待目标条件变量
int pthread_cond_wait(pthread_cond_t *cond, pthread_mutex_t *mutex);
POSIX 信号量
#include<semaphore>
//创建信号量
int sem_init(sem_t* sem, int pshared, unsigned int value)
/*
sem:初始化的信号量
pshared为0表示是当前进程的局部信号量, 否则信号量可以在多个进程间共享
value:信号量的初始值,设置为1可以当锁使用
*/
// 销毁信号量, 释放其占用的系统资源
int sem_destory(sem_t* sem)
// 以原子操作的形式将信号量的值 -1, 如果信号量的值为0, 则sem_wait将被阻塞直到sem_wait具有非0值 p操作
int sem_wait(sem_t* sem)
// 跟上面的函数相同不过不会阻塞. 信号量不为0则减一操作, 为0则返回-1 errno
int sem_trywait(sem_t* sem)
// 原子操作将信号量的值 +1 v操作
int sem_post(sem_t* sem)
进程池和线程池
进程池和线程池类似,基本上完全适用。
线程池就是服务器预先创建的一组子线程,线程池中的所有子线程都运行着相同的代码。当有新的任务到来时,主线程将通过某种方式选择线程池中的某一个子线程来为之服务。相比与动态的创建子线程,选择一个已经存在的子线程的代价显然要小得多。
-
主线程使用某种算法来主动选择子线程。最简单、最常用的算法是随机算法和 Round Robin(轮流 选取)算法,但更优秀、更智能的算法将使任务在各个工作线程中更均匀地分配,从而减轻服务器的整体压力。
-
主线程和所有子线程通过一个共享的工作队列来同步,子线程都睡眠在该工作队列上。当有新的任务到来时,主线程将任务添加到工作队列中。这将唤醒正在等待任务的子线程,不过只有一个子线程将获得新任务的”接管权“,它可以从工作队列中取出任务并执行之,而其他子线程将继续睡眠在工作队列上。
这感觉上其实和golang的channel+ select机制差不多,实际上我后续在这里的写法就是仿照go的模式来写的。
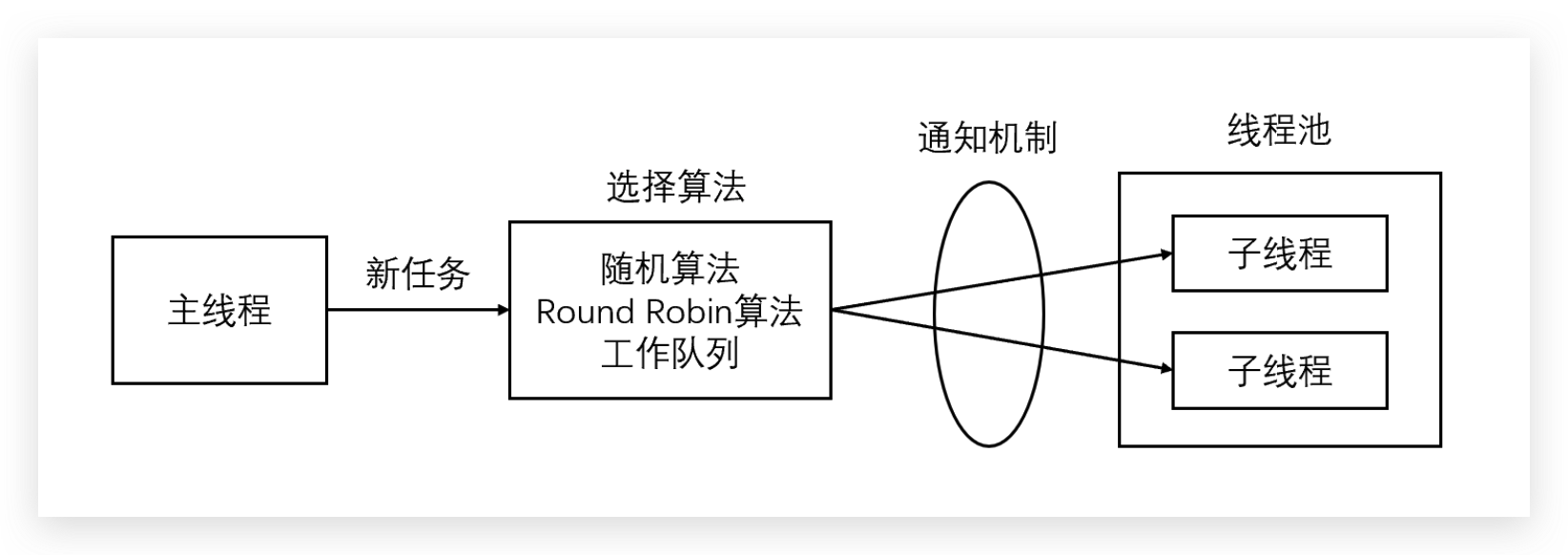
高性能服务器程序框架
书上把这一章内容放在了I/O复用之前,这是我没想到的。
服务器基础框架
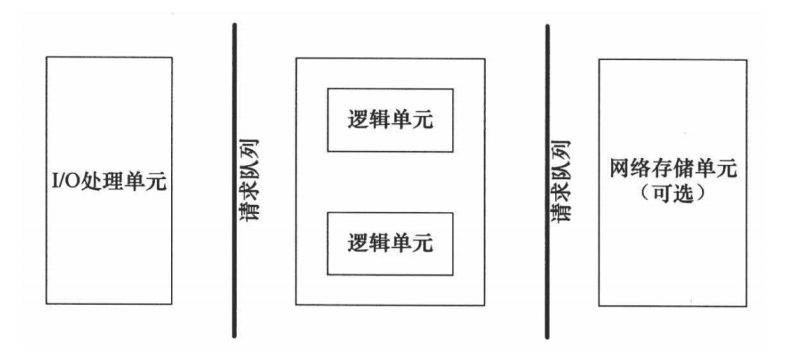
| 模块 | 功能 |
|---|---|
| I/O处理单元 | 处理客户连接,读写网络数据 |
| 请求队列 | 各个单元之间的通信方式 |
| 逻辑单元 | 业务进程或线程 |
| 网络存储单元 | 本地数据库、文件或者缓存 |
I/O 处理单元是服务器管理客户连接的模块。它通常要完成以下工作:等待并接受新的客户连接,接收客户数据,将服务器响应数据返回给客户端。数据的收发不一定在 I/O 处理单元中执行,也可能在逻辑单元中执行,具体在何处执行取决于事件处理模式。
请求队列是各个单元之间通信方式的抽象。请求队列通常被实现为池的一部分。
逻辑单元通常是一个进程或线程。它分析并处理客户数据,然后将结果传递给 I/O 处理单元或者直接发送给客户(具体使用哪种方式取决于事件处理模式)。服务器通常拥有多个逻辑单元,以实现对多个客户任务的并发处理。
网络存储单元可以是数据库、缓存和文件。
事件处理模式
服务器程序通常需要处理三类事件:I/O 事件、信号及定时事件。有两种高效的事件处理模式:Reactor 和 Proactor。
Reactor模式
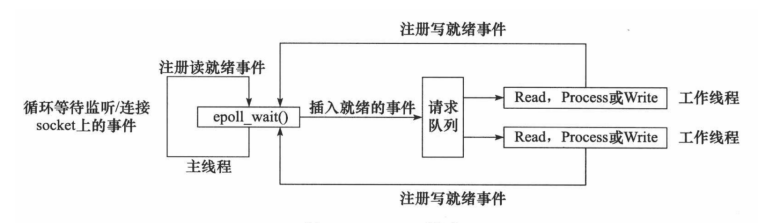
Reactor模式要求主线程(I/O处理单元)只负责监听文件描述符上是否有事件发生,有的话就立即将该事件通知工作
线程(逻辑单元),将 socket 可读可写事件放入请求队列,交给工作线程处理。除此之外,主线程不做
任何其他实质性的工作。读写数据,接受新的连接,以及处理客户请求均在工作线程中完成。
使用同步 I/O(以 epoll_wait 为例)实现的 Reactor 模式的工作流程是:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用
epoll_wait等待 socket 上有数据可读。 - 当 socket 上有数据可读时,
epoll_wait通知主线程。主线程则将 socket 可读事件放入请求队列。 - 睡眠在请求队列上的某个工作线程被唤醒,它从 socket 读取数据,并处理客户请求,然后往 epoll 内核事件表中注册该 socket 上的写就绪事件。
- 当主线程调用
epoll_wait等待 socket 可写。 - 当 socket 可写时,
epoll_wait通知主线程。主线程将 socket 可写事件放入请求队列。 - 睡眠在请求队列上的某个工作线程被唤醒,它往 socket 上写入服务器处理客户请求的结果。
Reactor 模式的工作流程图:
Proactor模式
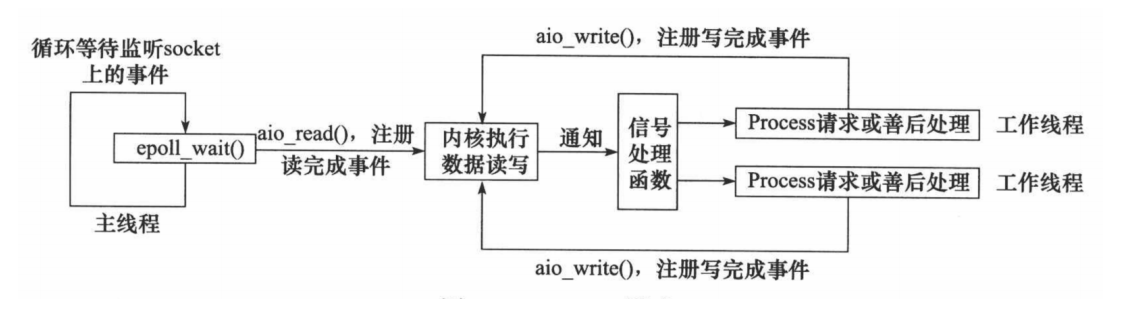
Proactor 模式将所有 I/O 操作都交给主线程和内核来处理(进行读、写),工作线程仅仅负责业务逻
辑。使用异步 I/O 模型(以 aio_read 和 aio_write 为例)实现的 Proactor 模式的工作流程是:
- 主线程调用 aio_read 函数向内核注册 socket 上的读完成事件,并告诉内核用户读缓冲区的位置, 以及读操作完成时如何通知应用程序(这里以信号为例)。
- 主线程继续处理其他逻辑。
- 当 socket 上的数据被读入用户缓冲区后,内核将向应用程序发送一个信号,以通知应用程序数据 已经可用。
- 应用程序预先定义好的信号处理函数选择一个工作线程来处理客户请求。工作线程处理完客户请求 后,调用 aio_write 函数向内核注册 socket 上的写完成事件,并告诉内核用户写缓冲区的位置,以 及写操作完成时如何通知应用程序。
- 主线程继续处理其他逻辑。
- 当用户缓冲区的数据被写入 socket 之后,内核将向应用程序发送一个信号,以通知应用程序数据 已经发送完毕。
- 应用程序预先定义好的信号处理函数选择一个工作线程来做善后处理,比如决定是否关闭 socket。
Proactor 模式的工作流程图:
同步方式的Proactor
上述所说的Proactor模式需要异步I/O接口,下述使用同步方式模拟:
- 主线程往 epoll 内核事件表中注册 socket 上的读就绪事件。
- 主线程调用 epoll_wait 等待 socket 上有数据可读。
- 当 socket 上有数据可读时,epoll_wait 通知主线程。主线程从 socket 循环读取数据,直到没有更 多数据可读,然后将读取到的数据封装成一个请求对象并插入请求队列。
- 睡眠在请求队列上的某个工作线程被唤醒,它获得请求对象并处理客户请求,然后往 epoll 内核事 件表中注册 socket 上的写就绪事件。
- 主线程调用 epoll_wait 等待 socket 可写。
- 当 socket 可写时,epoll_wait 通知主线程。主线程往 socket 上写入服务器处理客户请求的结果。
同步 I/O 模拟 Proactor 模式的工作流程:
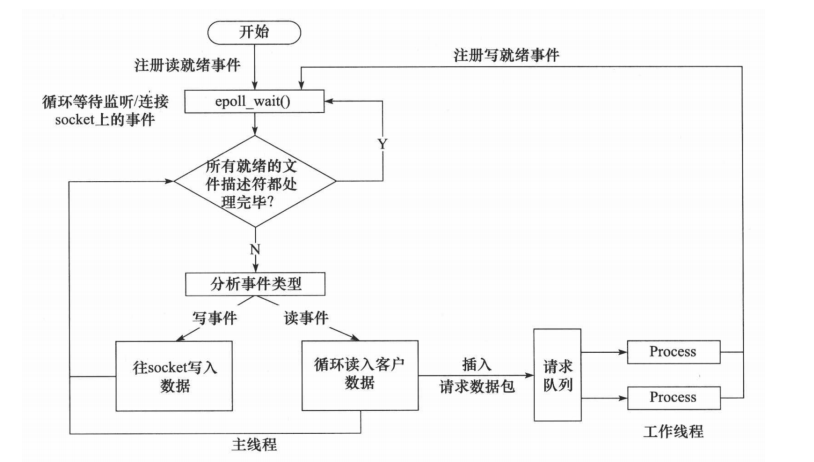
Reactor 模式和Proactor 模式的主要区别在于:对于工作线程而言,Reactor 发来的是已就绪的读写事件,而Proactor 发来的是已经完成的读写事件(异步I/O的处理在内核中完成,同步I/O在主线程自己实现)