
前言
开个新坑,本来是打算学学编译器的,但是发现基础太薄弱了,就先学习解释器相关吧,刚好大创也需要这一块的知识。
主要参考以下两本教材
概述
编译型语言
有的编程语言要求必须提前将所有源代码一次性转换成二进制指令,也就是生成一个可执行程序,比如C、c++、Golang等,这种编程语言称为编译型语言,使用的转换工具称为编译器。
解释型语言
有的编程语言可以一边执行一边转换,不会生成可执行程序,比如 JavaScript、PHP等。这种编程语言称为解释型语言,使用的转换工具称为解释器。
编译+解释
严格意义上python不算是单纯的解释型语言,其还会编译为pyc字节码,由pvm解释执行这个字节码文件,每一次负责将一条字节码文件语句翻译成cpu可以直接执行的机器代码。
java从源代码编译为字节码,然后在JVM上运行字节码执行,JVM是一种字节码的解释器,JVM的实现包括一个运行时的编译器,称为JIT(just-in-time)编译器,其最大的优势在于可以在运行时进行及时优化。更多关于JIT的知识可参考这篇文章.
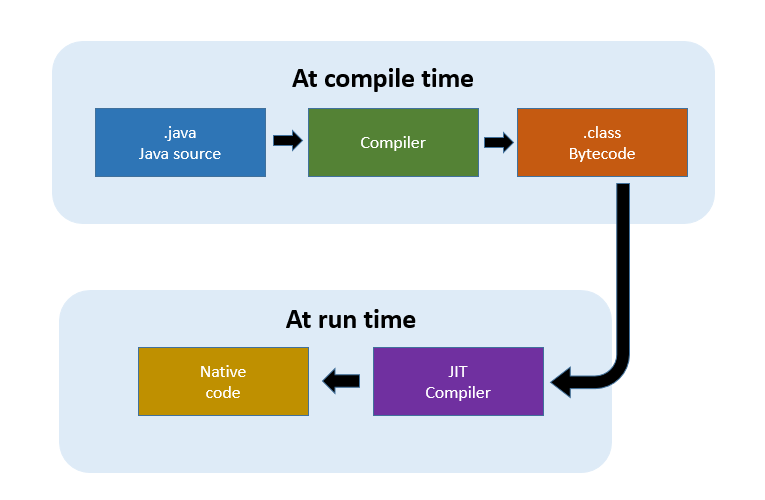
在知乎看到一个很有意思的提问:
我之前看知乎上有人分析,编译型语言能够直接生成二进制代码(Windows下就是EXE或DLL吧),而解释型语言不会生成二进制代码,最多道二进制代码的前一步。
我对这种解释有些无法理解,感觉这似乎不是他们的本质吧。Python是一个解释性语言,但我记得Python可以下载一个包,能够将Python直接编译为EXE可执行程序,难道说,我下载了这个包之后,Python就从解释型语言变为编译型语言了不成?
是这个概念区分本身就有严重的先天缺陷,还是我的理解本身有错误?
其中无论对与否,比较戳中我的回答:
语言只是规定语法,最后用这语言写出来的代码怎么翻译成机器码,怎么运行,还需要一个实现。这个实现可以是编译器也可以是解释器。
所以你也可以做一个python的编译器或者C语言的解释器
编译器构成
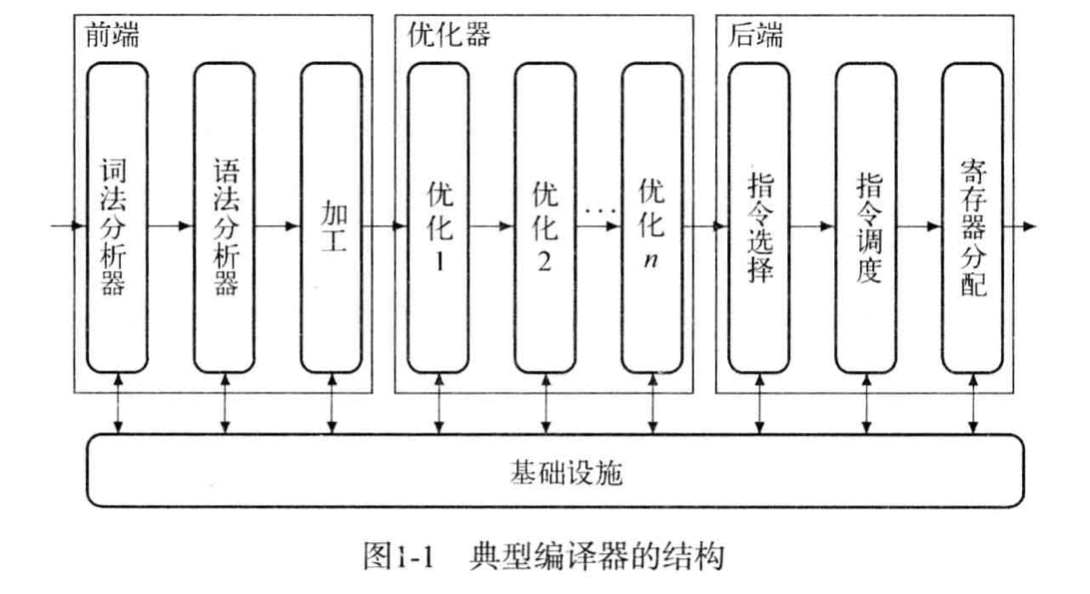
现在国内外大多教材(虽然我都没看过)在编译器这一块是头重脚轻的,比重前端»后端>优化器,虽然对于编译器这样非常不合理,不过站在学习静态分析的方向,更多的关注点还是放在前端,当然优化部分也不可忽视,比如这个值得反复揣摩的问答。
前端
前端部分,其实现有很多工具已经帮我们实现了
词法分析器
源代码在计算机『眼中』其实是一团乱麻。无法被理解的字符串在计算器看来并没有什么区别,为了理解这些字符我们需要做的第一件事情就是将字符串分组,这能够降低理解字符串的成本,简化源代码的分析过程。所有的编译过程其实都是从解析代码的源文件开始的,词法分析的作用就是解析源代码文件,它将文件中的字符串序列转换成 Token 序列,方便后面的处理和解析,我们一般会把执行词法分析的程序称为词法解析器(lexer)。
对于词法分析器而言,最繁杂的一步,也就是需要我们把这门语言可能用到的token全部枚举出来
package token
const(
// Identifiers + literals
IDENT = "IDENT" // add, foobar, x, y, ...
INT = "INT" // 1343456
// Operators
ASSIGN = "="
PLUS = "+"
// Delimiters
COMMA = ","
SEMICOLON = ";"
LPAREN = "("
// Keywords
FUNCTION = "FUNCTION"
LET = "LET"
TRUE = "TRUE"
......
)
我们采用类似解释器模式的python,逐行读取源文件,这里需要介绍两个函数
func (l *Lexer) readChar() {}
func (l *Lexer) peekChar() byte {}
readChar用于读取当前位置的字符,peekChar用于(看一眼)下个位置的字符,因为比如当读取到=时,无法断定token是赋值还是等于,需要通过下一个字符判断。
这里还有一个问题,我们如何判断一个变量呢,比如let x = 3,对于词法分析器而言let和x 是没有区别的,这里我们需要创建一个map
package token
var keywords = map[string]TokenType{
"fn": FUNCTION,
"let": LET,
"true": TRUE,
"false": FALSE,
"if": IF,
"else": ELSE,
"return": RETURN,
}
func LookupIdent(ident string) TokenType {
if tok, ok := keywords[ident]; ok {
return tok
}
return IDENT
}
这样每次当我们读完一串字符串,就进行LookupIdent寻找是否含有键值。
最后反复调用一个NextToken()函数,其内部调用readChar()以及token判断,这样最简易的词法分析器就暂时完成。
for tok := l.NextToken(); tok.Type != token.EOF; tok = l.NextToken() {
fmt.Printf("%+v\n", tok)
}
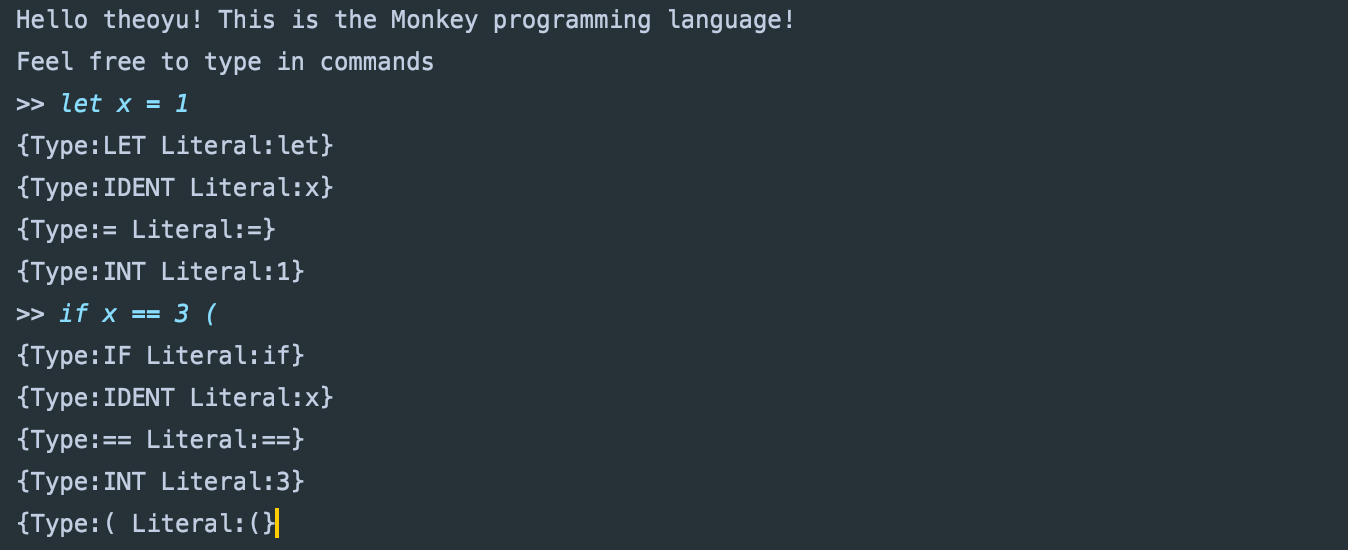
语法分析器
语法分析器就根据我们所定义的形式文法(Grammar)识别出词法分析所得到token的结构,从而构造出一颗语法树(AST abstract syntax tree),仅仅得到AST是不够的,还得对AST进行语义检查,保证其结构在语义上也是说得通的。
这一块真是看了好久才
看明白,其实是英语太拉垮了,拿着源码调试反而好理解一些。
拿最简单的let为例,let表达式通常是这样的:
let x = 10;
let y = 15;
let add = fn(a, b) {
return a + b;
};
......
let <identifier> = <expression>;
在我们创建结点之前,我们需要明白statements和expressions的区别,这两者本质的区别在于是否会产生值,比如声明 let x =5并不会产生值,但是5会.return 5不会产生值而add(5+5)会。(怎么感觉越说越糊涂)简单来说statements就是一句完整的语句,而expressions像是c++中的右值,需要一个变量去接收。现在我们创建两种类型的结点:
package ast
// The base Node interface
type Node interface {
TokenLiteral() string
String() string
}
// All statement nodes implement this
type Statement interface {
Node
statementNode()
}
// All expression nodes implement this
type Expression interface {
Node
expressionNode()
}
有了接口以后,我们需要为语法🌲创建一个根结点,
type Program struct {
Statements []Statement
}
func (p *Program) TokenLiteral() string {
if len(p.Statements) > 0 {
return p.Statements[0].TokenLiteral()
} else {
return ""
}
}
如果想把简单的let语句化为一颗AST,差不多是下面这样:
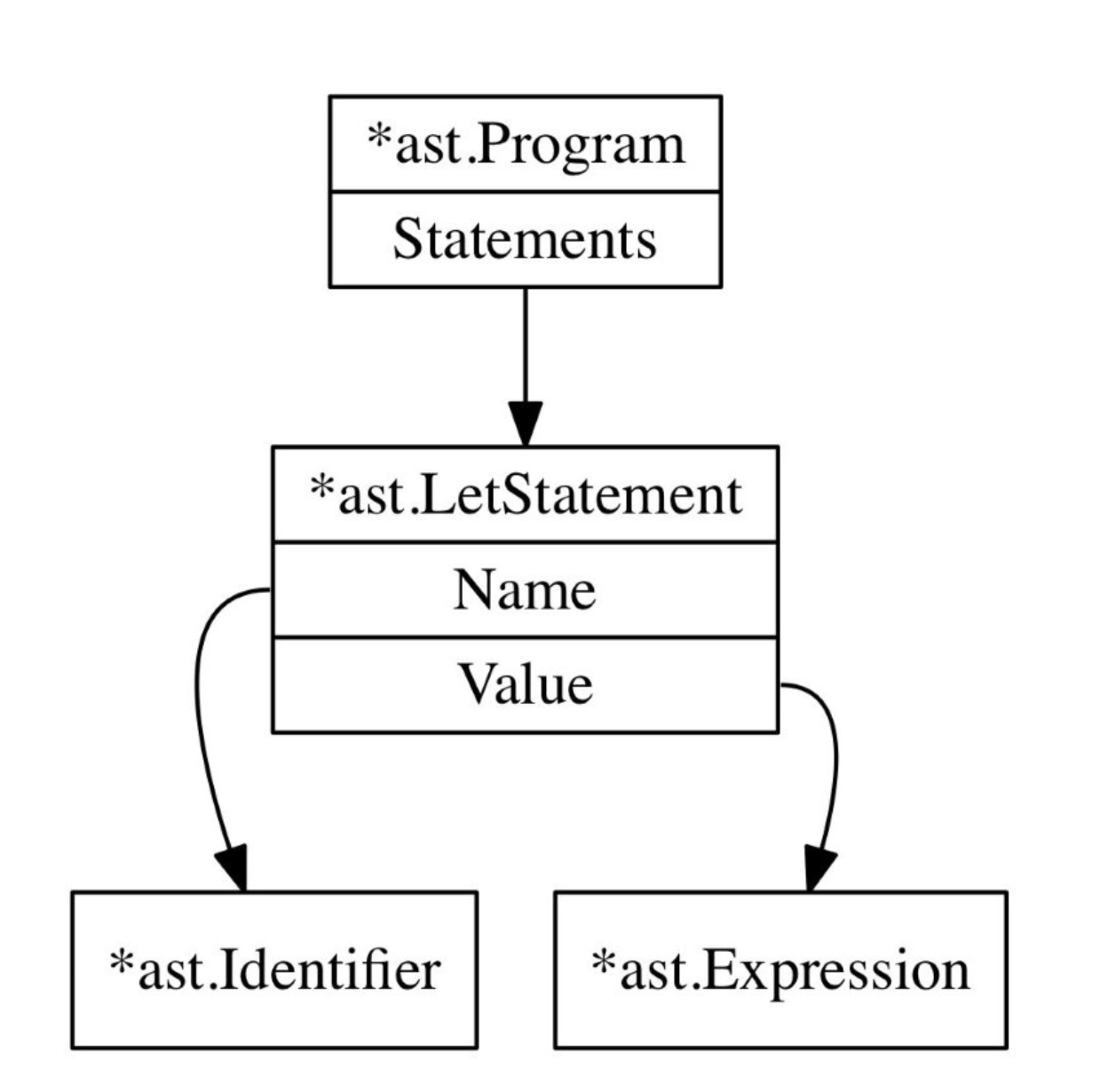
那LetStatement的雏形差不多有了:
type LetStatement struct {
Token token.Token // the token.LET token
Name *Identifier
Value Expression
}
那么当我们读到一个token为let,就可以进入对let的解析函数
func (p *Parser) parseLetStatement() *ast.LetStatement { stmt := &ast.LetStatement{Token: p.curToken} if !p.expectPeek(token.IDENT) { return nil } stmt.Name = &ast.Identifier{Token: p.curToken, Value: p.curToken.Literal} if !p.expectPeek(token.ASSIGN) { return nil } p.nextToken() stmt.Value = p.parseExpression(LOWEST) if p.peekTokenIs(token.SEMICOLON) { p.nextToken() } return stmt}
比如对于let x =5, 可以得到
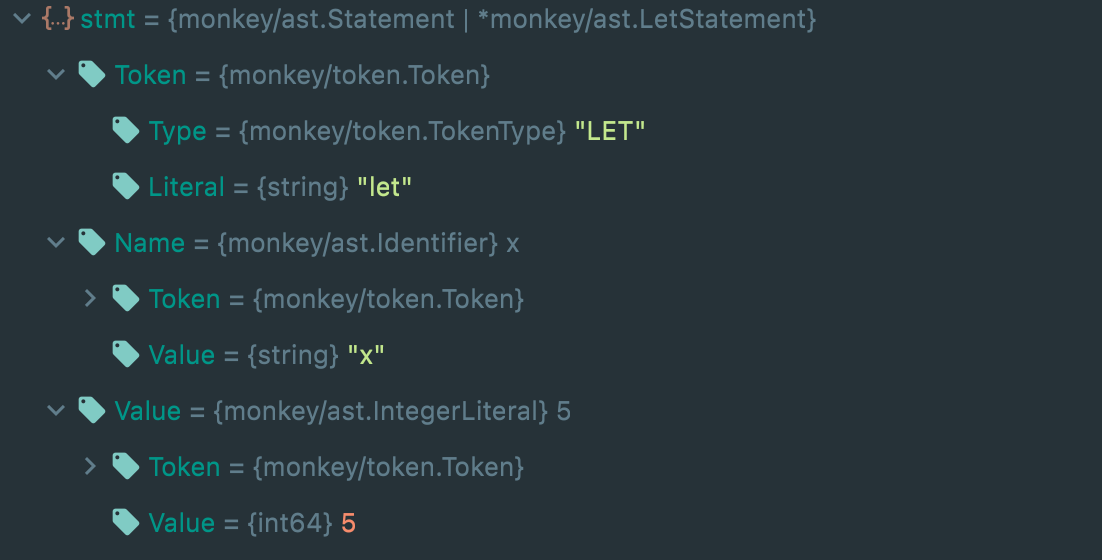
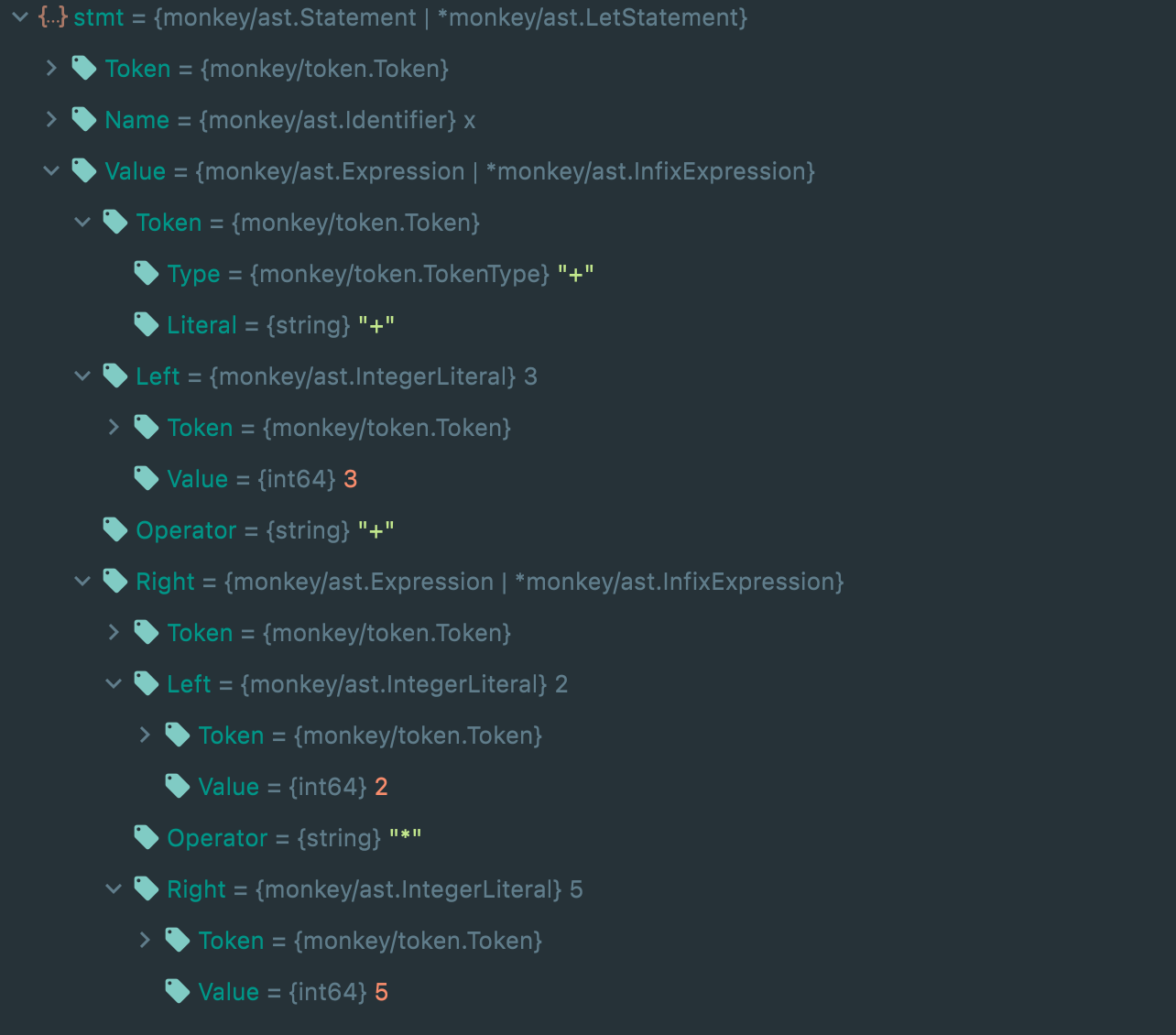
上面的例子的expression只是5,但比如let x = 3+2*5这种的表达式更为复杂,书中用到的方法叫Top Down Operator Precedence,或者Pratt Parsin。这里就不过多阐述,详细可参考原文章.
这样对于复杂表达式,我们也能解析:
优化器
代码部分并没有着重优化,书上理论部分实属抽象😭,但这其实又是静态分析中最重要的环节,容我学习学习……